LDAP Overview
Background:
LDAP stands for Lightweight Directory Access Protocol. It is a protocol that clients can use to request data from servers that speak LDAP. LDAP was designed to efficiently fetch data from a data management system (or DMS), with many session and security options. (A DMS is a more general term than DBMS (DataBase Management System) or RDBMS (Relational DataBase Management System), but it means much the same thing as far as a client program is concerned.)
Many
database products support LDAP queries such as Oracle and Microsoft Exchange.
In addition many client programs already support LDAP, including some web
browsers and mail clients. For example you can use “ldap://...” URIs to view
data using LDAP rather than HTTP or FTP
from your (modern) web browser. Example (personal info for Mark Smith):
ldap://ldap.itd.umich.edu/dc=umich,dc=edu??sub?uid=mcs
There are other public LDAP direcories you can query: ldap.bigfoot.com, directory.verisign.com, ldap.whowhere.com, and ldap.itd.umich.edu are some. Yahoo doesn’t have one anymore, but this used to work:
ldap://ldap.yahoo.com/??sub?&(sn=Pollock)(c=US)
which
starts an LDAP connection to Yahoo, sends a request to search for all people
whose surname matches “Pollock” and who live in
the U.S., and return the results.
Most web browsers no longer support ldap:// protocol. You must configure them to use some external client application to handle the returned data. On Windows use Address Book (wab.exe).
LDAP
was designed to support the most useful subset of an earlier standard for
directory access, X.500. X.500 is a
heavyweight DMS that is difficult to fully and correctly implement. It
contains many features that turn out to be rarely necessary. LDAP is now
documented in RFC-4510.
Most DMSs such as SQL, JDBC, or ODBC emphasize language aspects. However LDAP is more generally thought of as a way to connect clients to data sources in a transparent manner. It is thus more often thought of as a protocol similar to FTP or SMTP (Simple Mail Transfer Protocol). Most popular DMSs support concepts of transactions, concurrency management, and the other elements of the ACID (atomic, consistent, isolated, and durable) criterion. But LDAP is “lightweight” in that it doesn’t model these features; they generally aren’t needed to provide a lookup service. From an application programming perspective however, LDAP is just another client/server DMS.
Directories and Schemas:
While any database can support LDAP (i.e., accepts LDAP queries using the LDAP protocol, and return LDAP formatted results), it is usually used with a type of DB called a directory. A directory is a special kind of database that is designed to support browsing, as well as quick lookups and searches of data. Directories tend to contain descriptive, attribute-based information and support sophisticated filtering capabilities. Examples include address books (with attributes such as name, phone number, address, etc.), bookmark lists, server configuration, host name information, user account information, DNS information, company directories, roaming user preferences, user and password information, etc.
A server that provides access to a directory of information provides a directory service.
Directories generally do not support complicated transaction or roll-back schemes found in database management systems designed for handling high-volume complex updates. Directory updates are typically whole record insertions, deletions, and replacements, but generally not updates to individual attributes. Updates may not be allowed at all if the data is read-only (which is often the case); then you need to update the data by editing files or using LDAP server tools.
Directories are fine-tuned to provide quick responses to high-volumes of lookup and/or search operations. They may have the ability to replicate information widely, in order to increase availability and reliability and at the same time reducing the response time. And if directory information is replicated, temporary inconsistencies between the replicas are allowed as long as all copies converge eventually to a consistent view of the data.
DNS is a common example directory.
Each type of entry (record) in a directory is described in a schema. A schema is a collection of different object (record type and container type) descriptions. A given object may be described by several different schemas. (I.e., a given record may be described by both person and employee schemas.) In a single directory you may have objects (records) of different types: persons, printers, etc.
The most commonly used LDAP server is OpenLDAP (“slapd”). The current version supports extensions (called overlays), many different back-ends (the actual DB holding the data), and is actively maintained. However it is far from simple to configure and deploy.
HP provided financial support for the current version and adopted OpenLDAP for their Enterprise Directory world-wide in 2006. Today (9/2007) HP is accessing their OpenLDAP directories fifty million times a day, or over a billion and a half times a month.
There are other vendors of directory service products that use LDAP: Solaris has one, Red Hat has one called Fedora Directory Server, and a third open source one called Open DS. But OpenLDAP is the one you will most likely need to know in the real world, so we will set that up.
Some benchmarks on a typical server configurations show that, with sufficient RAM to cache active data, OpenLDAP answers twelve to fourteen thousand queries a second, better than all current competition (open or proprietary).
In addition to a server slapd, OpenLDAP includes plug-ins for many different back-ends, some overlays, the replication server syncrepl (previously called slurpd), some client libraries so applications can use it, and many command line utilities named ldap* (useful from scripts).
While using LDAP for single sign-on (central user data DB) is very attractive, all single sign-on DBs suffer from network latency (delay) or outage, and without a more complex replicated setup they also become a single point of failure.
Some companies today prefer to use cfengine or similar tools to synchronize the various password files to each host after every change. Then each server just needs local, simple access.
Replication
A directory replication capability (called syncrepl in OpenLDAP) is used to synchronize the changed made to a master copy of the directory to other servers that maintained copies of part or all of the directory. Replication lets enterprises place copies (complete or partial) in various parts of their network to optimize for performance and reliability. syncrepl pushes the changes out to replica servers as updates are made to the master directory.
Object Classes, Attributes, and Entries
The LDAP information model is based on entries (a.k.a. records, objects, nodes, or rows). An entry is a collection of attributes (a.k.a. fields or columns) that has a globally-unique Distinguished Name (DN). The DN is used to refer to the entry unambiguously. Since LDAP entries are arranged in a hierarchy you can think of DNs as analogous to absolute pathnames. Some entries are containers (like a filesystem directory) and others are leaf entries (like a file).
Each
of an entry’s attributes has a name, a type, and one or
more values. The attributes typically use mnemonic string for
names, such as “cn” for common name (every leaf has one) or
“mail” for email address. The syntax of values depend on the attribute type.
For example, a “Full Name” attribute might contain the value “Hymie Piffl”. A “mail”
attribute might contain the value “hpiffl@acme.org”. A “Photo”
attribute might contain a GIF or JPEG graphic (non-text type). An “Age”
attribute might contain an integer. To read and search data in a directory the
schemas used must be available and known to the data manager (LDAP server), or
it can’t serve up such data.
Each entry has a type known as its object class, that defines which attributes are allowed and which are required for entries of that class (type). Some object classes are extended from others (in Object-oriented programming terms, inherited, or sub-classed). The class “top” (and “alias” too) is at the root of the hierarchy of object class types.
A given entry can have multiple object classes, in which case the union of legal and required attributes of each object class applies to this entry. Some attributes can be repeated, others can’t be.
Annoyingly, some object classes depend on others, so an entry that uses one must use all the ones it depends on (and there is no easy way to tell what the dependencies are.) For example, the “organizationalPerson” object class is a subclass of the “Person” object class, which in turn is a subclass of “top”. RFC-2256, section 7, and RFC-1274, Appendix C, lists required (“MUST”) and allowed (“MAY”) attributes, and super-classes, for many standard object types.
When creating a new LDAP entry you must always specify all of the object classes to which the new entry belongs. Because OpenLDAP does not support object class subclassing, you also must always include all of the superclasses of the entry. For example, for an “organizationalPerson” object, you should list in its object classes the “organizationalPerson”, “person”, and “top” classes. (Other LDAP servers are smart enough to figure that out automatically.)
Many LDAP (and X.500) object classes are defined in RFCs. A few common ones are not (Red Hat includes a few), and you can define new ones anytime. Object classes and attributes are defined by their OIDs, the same ASN.1 numbers used for SNMP. For example, “2.16.840.1.113730.3.1.1” is the number for the “carLicense” (license plate number) attribute of the “inetOrgPerson” object class.
Defining the schema is the hardest part of setting up any database! You need to decide what applications will use your LDAP server, and what data they need. Applications will have specific field names and types needed for LDAP support. Each of these definition sets could be considered a piece of the overall schema.
You can define your own applications and your own schemas for each one, but there are a number of standard schemas that come with the OpenLDAP distribution. Many common applications (such as pam_ldap) are available that only need these standard object classes. You need to use the right mix of these standard schemas to support the entire range of applications you plan to run using a single LDAP server.
Summary: If your directory (database) will include records (entries) for users and printers, then you must include both schemas.
Directory Structure
With LDAP directory entries are arranged in a hierarchical tree-like structure of container nodes and leaf nodes. Container nodes are entries too, but they contain other container nodes and leaf nodes. Leaf nodes represent records of data usually called entries or objects.
Traditionally this structure reflects the geographic and/or organizational boundaries. Each organization starts with a top container node called the root object. For large multinational organizations, entries representing countries appear at the top of the tree below directly below the root. Below them are entries representing state and national organizations. Below them might be entries representing organizational units (departments), people, printers, documents, etc. Such tree-like organizations facilitate searching and partitioning of the data.
The
distinguished name of any entry can be thought of as a pathname from the root
to the leaf node for that entry. The name and type of each node along the path
is included in the name. An example DN might be “dc=acme,dc=com”. Here are a couple of examples
of possible directories. The one on the right shows a DNS based approach:
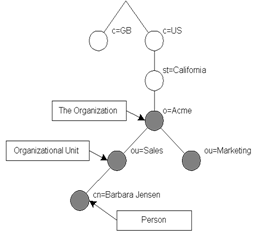
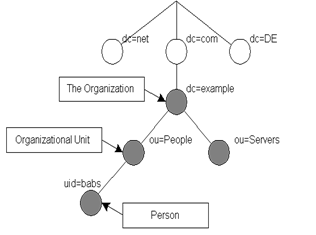
LDAP defines operations for interrogating and updating a directory. Operations are provided for adding and deleting an entry from the directory, changing an existing entry, and changing the name of an entry. Most of the time, LDAP is used to search for information in the directory. The LDAP search operation allows some portion of the directory to be searched for entries that match some criteria specified by a search filter. Information can be requested from each entry that matches the criteria.
For
example you can easily search an entire directory sub-tree at and below dc=acme,dc=com for people with the name Hymie Piffl, retrieving the email address of each
entry found. Or you might want to search the entries directly below the st=Florida,c=US entry for organizations with the
string Acme in their name
and that have a fax number.
LDIF
The LDAP Data Interchange Format (LDIF) is used to represent LDAP entries in a simple text format. (See ldif(5) man page.) The technical specification for LDIF is RFC-2849. While each LDAP server stores data internally in some server-specific way, it is possible to export data from one server, to import into another. LDIF is the standard format used for this, and is supported by nearly every LDAP application and server (Outlook, Thunderbird, ...).
The file format may be text but it can be complex and confusing. There are a number of GUI tools to create LDIF files for you. In addition, there are a number of (usually Perl) scripts that can create LDIF data files from standard system files, such as /etc/passwd.
An LDIF file consists of entries, separated by blank lines. Lines starting with “#” are comment lines. Each entry starts with the “dn:” of the entry. All attributes are written one per line. A line that starts with a single space or tab is a continuation of the previous line (the newline and the one space/tab are removed as if they weren’t there). The basic form of an LDIF entry is:
dn: distinguished
name
attrdesc: attrvalue
...
The attrdesc is the name of some attribute for the entry such as objectClass or 1.2.3 (an OID associated with an attribute type), and may include options (for example cn;lang_en_US or userCertificate;binary).
The attrvalue may be specified as UTF-8 text, as base64 encoded data, or as a URI (to provide the location of the attribute value). The exact nature of the value depends on the definition of the attribute; some are numbers, others a filename, but most are plain text.
Where it gets tricky is that base64 values are preceded by a double colon, and URIs are preceded by “:<”. If an attrvalue contains non-printing characters, or begins with a space or a colon (‘:’) or a less than symbol (‘<’), then you must use the base64 encoding scheme (and remember the double colon!).
Here is an example showing all three variations:
# Entry of user bjensen:
dn: cn=Barbara J Jensen,dc=exam
ple,dc=com
cn: Barbara J Jensen
cn: Babs Jensen
objectclass: person
description:< file:///home/bjensen/.plan
sn: Jensen
jpegPhoto:: /9j/4AAQSkZJRgABAAAAAQABAAD/2wBDABALD
A4MChAODQ4SERATGCgaGBYWGDEjJR0oOjM9PDkzODdASFxOQ
ERXRTc4UG1RV19iZ2hnPk1xeXBkeFxlZ2P/2wBDARESEhgVG
...
Note: You can pipe (echo or cat) data through the recode command to convert it to base64:
echo ':starts with a colon' | recode ../Base64
This covers the basic file format, but each entry can include additional lines, to allow you to use LDIF files to change, add, and delete attributes of entries, and to delete, rename, and move entries.
Components in an LDAP Data Management System:
There are at least four components in a client-server data management system that will use LDAP:
1. A data manager (i.e., the server)
2. A data schema or collection of schemas that the data manager can support
3. Data or content that respects the schema and can be loaded into the data manager
4. A client application that accesses the data
You need to assemble these elements and configure them all to cooperate with each other.
LDAP the protocol versus LDAP the server
While client and server programs can be designed to use LDAP directly, today it is common to be concerned with security, correctness, robustness, and efficiency. All of which are hard to program yourself every time you want to develop some client or server. So instead of talking directly with some server, clients speak with an intermediary server. The intermediary server is in turn configured to communicate with various data sources called back-ends. This intermediary server is also configured to negotiate all session and security aspects. Such a product is (confusingly) also known as a data manager.
You can think of an LDAP data manager as a convenient and consistent front-end view to a whole range of DMS technologies. Real-world LDAP back-ends use everything from a network information system (NIS) account registry to conventional relational database management systems(RDBMSs) such as Informix and DB2. (Oracle does LDAP directly.) Application programmers can develop e‑mail projects, corporate directories, course catalogs for colleges, form repositories, search engines, etc., without concerning themselves about where the actual information is coming from. User account information may, for example, come from personnel department files on a mainframe, NIS logins on engineering workstations, a Windows NT domain controller, or someplace else.
Today there is a product called OpenLDAP, which is a popular, free, and open data manager, that speaks to clients using LDAP. OpenLDAP comes with an API to easily create clients, and it also comes with several command line tools that can be used in scripts. Here’s an example command line tool that repeats the search shown earlier:
ldapsearch -h ldap.yahoo.com "&(sn=Pollock)(c=US)"
(GUI LDAP clients are available: kldap, phpLDAPadmin, and gq. Most email clients, including Thunderbird, support LDAP for address book information.)
OpenLDAP is not a database directly but rather an intermediary that can serve data to clients from an ever-growing list of database server “back-ends”. With OpenLDAP you can use nearly any back-end from plain text files to relational database servers such as MySQL. Note a single OpenLDAP server can serve many different directories at once, from multiple back-ends.
When using a data manager such as OpenLDAP on a production system, there are six components to configure:
1.
The OpenLDAP data manager (i.e., the server, called slapd)
2. A data schema that the data manager can support
3. A back-end DMS that actually serves the data
4. Data or content that respects the schema and can be loaded through the data manager
5. A configured security layer that OpenLDAP can use
6. A client application that accesses the data
Configuration:
OpenLDAP is very commonly used on both Linux and Unix, however it does have a number of limitations and quirks that make configuration tricky. There is at least one new open source LDAP server being developed, however it isn’t widely used at this time.
Besides the OpenLDAP client and server software packages, you’ll need to install several other packages. nss_ldap to support LDAP from the nsswitch.conf mechanism and for PAM, GUI LDAP tools, LDAP support for PHP, Perl, email, Apache, and other software without built-in LDAP support.
You can find all sorts of information about configuration on the web, especially from OpenLDAP.org.
OpenLDAP allows you to control the access to the data and the security of the sessions. It has many settings to permit fine-grained control over how clients can talk to the sever (negotiation of various session parameters, such as encryption), who can talk to the sever (client authentication), what data clients can view (client authorization), and other details. The security configuration is perhaps the most difficult part of the configuration of OpenLDAP. OpenLDAP supports a great number of choices for each facet of security, including the ability to use a SASL (“Simple Authentication and Security Layer”) library such as the ones from Cyrus or Gnu. SASL also has complex configuration.
Fortunately, for development and learning purposes you can configure your firewall (and/or TCP Wrappers) to ignore all LDAP requests from anywhere except the localhost. Then you can ignore (for now) the security settings and concentrate on getting the server up. This involves several steps:
1. Make sure your OpenLDAP packages are installed and up to date
2. Make sure your firewall doesn’t permit external LDAP requests (those coming in to ports 389 [LDAP] and 686 [LDAPS] )
3. Creating a directory containing a couple of records
4. Configuring OpenLDAP to serve this directory
5. Configuring OpenLDAP to run at boot time.
After this you use the command line tools to test your service. Use the log files for (hopefully) helpful error messages if things don’t seem to be working. Finally add some additional data to your directory and have fun using it.
1.
Edit the slapd.conf
configuration file. This file is the configuration file for the OpenLDAP
server and is found in /etc/openldap.
It contains various directives you can un-comment or comment.
o The
first section contains include
directives for the schema files you wish to use.
o You can define the versions of LDAP clients that you will support.
o Next are some file locations, the defaults are fine.
o The
moduleload directives are
used to provide support for the type of back end data source you plan to use if
openldap was compiled for modules. (Not on Fedora!) Just un-comment
the appropriate ones for your DBM.
o The next section of this file describes the security you plan to provide. You can use TLS to encrypt the sessions, and also provide access control to restrict who can do what with your data. Each part of the LDAP tree can include different access controls, which may be based on user or location (IP Address).
o The rest of the file contains one or more database descriptions. For each you include the DB type, the directory name (and suffix), the password for the administrator (root distinguished name) of this database (the root password), the directory where the LDAP server will put its files for this DB, and other DB-specific information, such as what indexes to maintain and replication information.
An
example using a Berkeley database file for a back-end might look like this, for
a DB that defines a “Manager” role for
employees to assume:
database bdbsuffix "dc=example,dc=com"rootdn "cn=Manager,dc=example,dc=com"rootpw secretdirectory /var/ldap/example.com-data
Note
it may not be the best idea to include a plain text password in this file. It
is also permissible to provide hash of the password in RFC-2307 form. slappasswd may be used to generate the
password hash. For example the command “slappasswd -s secret” results in a hashed password you can
copy into the configuration file:
rootpw {SSHA}ZKKuqbEKJfKSXhUbHG3fG8MDn9j1v4QN
With the “-h 'scheme'” option you can use different hash schemes (such as '{MD5}'). While the “-s” option allows this command to be scripted, it is not secure to have your password on the command line (ps listing, .history file). Leave this out and the program will run interactively, prompting you for the password.
2. Check ownership and
permissions. The group and user that slapd runs as is supplied on the
command line when starting this tool, not (as one would expect) in the
configuration file. On Red Hat like systems options for servers are stored in
files named for the service, under /etc/sysconfig.
On Fedora the default is user and group ldap/ldap. Oddly OpenLDAP switches to this
user/group before attempting to read its configuration file. The bottom
line is all files in /etc/openldap/*
must be set to mode 0600 for security, with owner/group of ldap/ldap
(including for the directory itself), or the server will mysteriously fail to
run:
chown -R ldap.ldap /etc/openldap
chmod 600 /etc/openldap/*
chmod 700 /etc/openldap # 755 ok for low-security
This setup will cause problems on reboot. Newly created DB files may have the wrong owner. Also, Berkeley DB wants a DB_CONFIG file (even if empty) or you get a warning. So:
cd /var/lib/ldap
touch example.com-data/DB_CONFIG
chown -R ldap.ldap . # Do this after running once.
3.
Start slapd.
Check for any error messages in the log files that would indicate a
mis-configuration. Check that the LDAP server is listening on the correct
port. If all seems to be okay, test out the server using a search:
ldapsearch -x -b '' -s base '(objectclass=*)' \
namingContexts
(Don’t forget the quotes.) This should return the following:
dn:namingContexts: dc=example,dc=com
4.
Add some records to the database. The OpenLDAP command line tool
uses the standard “LDIF”
file format to contain data. You create this file using vi (in real life an application creates
the data to add in the correct format, or you can use a special GUI tool).
(See the ldif man page.) A
sample LDIF file (see LFIF-data.txt
resource) might look like this:
dn: dc=example,dc=comobjectclass: dcObjectobjectclass: organizationo: Example Companydc: example dn: cn=Manager,dc=example,dc=comobjectclass: organizationalRolecn: Manager
You can have multiple records defined in one LDIF file, each starting with the “dn:” line (and separated with a blank line?). The LDIF file entries show data to add, data to change, or data to delete from the LDAP database, depending on the command line tool used.
OpenLDAP supports an extended format documented in the slapd.replog(5) man page. This permits extra entries such as the “changeType:” pseudo-attribute, which allows a single data file to contain additions, modifications, and deletions. This is useful when you need to synchronize a replica from the change log of the master LDAP server.
If you don’t say what to do with a “changeType:” line, the default is to add the data if using the ldapadd tool, and to modify it if using ldapmodify tool (which is a hard link to the same program). There is also an ldapdelete command to delete matching data.
Next
add your data using the ldapadd command. Then
repeat the ldapsearch command to see
if the new record is found:
ldapadd -x -D "cn=Manager,dc=example,dc=com" -W \
-f example.ldif
ldapsearch -x [-LLL] -b 'dc=example,dc=com'
OpenLDAP tools can use default options to simplify the use of the command line tools, for example the default base DN to use. These options go in /etc/openldap/ldap.conf file. Do not confuse this file with /etc/ldap.conf, which is not part of OpenLDAP at all, but the nss_ldap package (i.e., used to configure pam_ldap).
Additional considerations
An LDAP server used for vital services (such as login) must be secure and reliable as possible. Frequent backups of the data are desirable. However, if the LDAP server fails for any reason (or the back-end data store), nobody could log into the network. Accordingly you should deploy an LDAP server with similar considerations as a DNS server. In this case this means you should replicate the LDAP server.
A replica is a second server that serves the same data. This second server get the current data from the primary server. Unlike a slave DNS server, which periodically polls the master to check for updates, OpenLDAP runs a program on the master LDAP server, watching for changes and pushing the update to the replicas. For OpenLDAP the stand-alone server that does this is called syncrepl. If deploying a replica, you must make sure your firewall allows syncrepl to transfer the data work.
If the master OpenLDAP server fails, clients can look up data from any replica. However replicas don’t support updates. Some (commercial) LDAP servers work differently but OpenLDAP is so common you may want to handle this situation. The solution is to use clustering technology. For Linux see Linux-HA.org (Highly Available Linux Project). You first set up a virtual IP address for your LDAP service. The redirector (or router) uses a form of DNAT to sent all LDAP traffic to the master LDAP server. The replica is unused but is running so updates from syncrepl are handled. Another component called the heartbeat monitor checks the master server continuously, by tracking a type of keep-alive packet sent and replied to regularly.
If the heartbeat monitor thinks the master has died, it will switch the virtual IP address to forward packets to the replica instead. Using some clever scripting, you can have the replica change its type to master at this point, so as to accept updates.
When the original master comes back on-line, it should be brought up as a replica. Then you can continue to use the current server as the master, or kick the heartbeat monitor in the head to switch ‘em back to the original configuration. (This would be useful if the standby hardware wasn’t as powerful as the main server.)
LDAP Versions and References:
LDAPv1 (RFC-1487) was the first cut at a lightweight X.500 and isn’t used anymore. It was developed in the early 1990s. (The RFC is historic only.)
LDAPv2 technical specification (RFC-3494) is also historic, but continues to be used in some places. As most implementations of LDAPv2 do not conform to the LDAPv2 technical specification, interoperatibility amongst implementations claiming LDAPv2 support is limited. LDAPv2 also differs significantly from LDAPv3, so deploying both LDAPv2 and LDAPv3 simultaneously can be quite problematic. LDAPv2 should be avoided.
LDAPv3 was developed in the late 1990’s to replace LDAPv2. LDAPv3 adds the following features to LDAP:
· Strong Authentication via SASL
· Integrity and Confidentiality Protection via TLS (SSL)
· Internationalization through the use of Unicode
· Referrals and Continuations
· Schema Discovery
· Extensibility (controls, extended operations, and more)
The Lightweight Directory Access Protocol version 3 (LDAPv3) was specified by this set of ten RFCs but is now described in a single RFS, 4510:
|
LDAP RFCs and their descriptions |
|
|
RFC2251 |
Lightweight Directory Access Protocol (v3): The specification of the LDAP on-the-wire protocol |
|
RFC2252 |
Lightweight Directory Access Protocol (v3): Attribute Syntax Definitions |
|
RFC2253 |
Lightweight Directory Access Protocol (v3): UTF-8 String Representation of Distinguished Names |
|
RFC2254 |
The String Representation of LDAP Search Filters |
|
RFC2255 |
The LDAP URL Format |
|
RFC2256 |
A Summary of the X.500(96) User Schema for use with LDAPv3 |
|
RFC2829 |
Authentication Methods for LDAP |
|
RFC2830 |
Lightweight Directory Access Protocol (v3): Extension for Transport Layer Security |
|
RFC3377 |
A list of RFCs for LDAP (v3) |
|
RFS3771 |
LDAP Intermediate Response Message [Format] |
RFCs may be found at a number of places on the Internet, including http://www.faqs.org/rfcs/. See also RFC-2222 (the description of SASL) and Gnu gsasl reference manual and Cyrus SASL reference manual for information on specific SASL implementations.
Application Configuration:
Many
applications and servers can be configured to use LDAP instead of their own
files. These include login (you can
configure PAM to use LDAP rather than /etc/passwd, /etc/shadow, and related files), sendmail (or other MTAs
(email servers), POP and IMAP servers,
Samba, Mozilla/Netscape, various email clients, and many others. By including
the correct schemas (or creating your own) you can avoid duplicating
information needed by several servers (for instance, sendmail and POP can use
the same user list). You also keep all information in a central repository,
which you can more easily replicate than trying to provide such features for
many individual servers. Backups become more simple as well.
Each application has its own way of using LDAP. Consult the documentation available for each application you wish to configure. Note that not all applications or servers today can use LDAP.
To use LDAP to replace /etc/{passwd,group,shadow,gshadow} files you need to install the nss_ldap package. This allows you to configure /etc/nsswitch.conf to use LDAP as a primary source of aliases, ethers, groups, hosts, networks, protocol, users, RPCs, services, and shadow passwords (instead of or in addition to using flat files or NIS).
This package also provides a pam_ldap PAM module you can use with any PAM-ified client. Interestingly the two don’t work exactly the same way. If you configure nsswitch.conf to use LDAP for passwords, the standard pam_unix module will use LDAP. So why do you need pam_ldap too?
pam_unix will attempt to fetch (read) the password from the source, /etc/shadow or LDAP. That requires read permission on the password entry for anonymous users. Not a good idea! Pam_ldap just tries to bind to the server (that is, log in) without reading anything. It uses the information from /etc/ldap.conf, not to be confused with /etc/openldap/ldap.conf (defaults for openldap client tools). If the login is successful the supplied password must be okay.
In addition not all PAM-ified applications are supported by nsswitch.conf. Also the pam_unix module doesn’t handle password changes for ldap well, or LDAPv2 clients, or some servers, so you need to configure pam_ldap for that. See the nss_ldap package information (rpm ‑qi nss_ldap) for more details.
Using LDAP for accounts, groups, and passwords
[ From en.wikibooks.org/wiki/Linux_Guide/LDAP_authentication_in_Linux, posted Friday, December 09, 2005 by swapnil_durgade@yahoo.com ]
1. Make sure the required packages are installed:
openldap-2.2.23-5.i386.rpm
openldap-clients-2.2.23-5.i386.rpm
openldap-servers-2.2.23-5.i386.rpm
2. Configure OpenLDAP: Edit file /etc/openldap/slapd.conf and change at least these settings:
suffix "dc=example,dc=com"
rootdn "cn=manager,dc=example,dc=com"
rootpw yourrootpassword
3. Start OpenLDAP: Run the command service ldap start
4. Use Migration Script to create ldif files from /etc/passwd and /etc/group:
Edit /usr/share/openldap/migration/migrate_common.ph:
$DEFAULT_MAIL_DOMAIN = "example.com";
$DEFAULT_BASE = "dc=example,dc=com";
Create ldif files in /root (home) directory with the following:
./migrate_group.pl /etc/group ~/group.ldif
./migrate_passwd.pl /etc/passwd ~/passwd.ldif
./migrate_base.pl > ~/base.ldif
5. Import ldif files into OpenLDAP:
ldapadd
-cx -D "cn=manager,dc=example,dc=com" \
-w yourrootpassword -f ~/base.ldif
ldapadd
-cx -D "cn=manager,dc=example,dc=com" \
-w yourrootpassword -f ~/passwd.ldif
ldapadd
-cx -D "cn=manager,dc=example,dc=com" \
-w yourrootpassword -f ~/group.ldif
6. Configure PAM for ldap authentication: Use authconfig (a RH cmd)
On the first screen select Use LDAP and Use LDAP Authentication.
On
the next screen, type Server: 127.0.0.1
Base DN: dc=example,dc=com
Or you can edit the various files in /etc/pam.d directly. Add to system-auth (and/or to other files):
ZZZ
Other Application Configuration:
Apache can be configured to use LDAP instead of its htgroup and htpasswd files. See mod_authz_ldap RPM package for the Apache module you need.
LDAP and Kerberos can be used together to set up a enterprise scale single sign-on system, including a mixture of Linux, Unix, and Windows hosts.
LDAP and an automount daemon are often used together. You store the automount map files in LDAP, rather than in files on your various file servers.
Solaris LDAP Notes from docs.sun.com/app/docs/doc/816-4556/6maort2te?a=view
1) BOTH the
posixAccount and shadowAccount are required in the People entries (and your ldif when you use it to add), or
else some error like “Unknown user id” or “invalid credentials” will occur to
login process.
An extra “objectClass: person”
definition will make it more compatible with SUN ONE Console.
2) It is important that passwordStorageScheme of DS5.2 server is defined as “crypt” using “idsconfig” or SUN ONE Console, so that legacy passwords from /etc/shadow or NIS gets migrated properly and the login process has fewer issues.
3) Separate ou=shadow is logically not required as /etc/passwd and shadow passwords (/etc/shadow) should all be stored in the same ou=People container.
4) The definition of serviceSearchDescriptor in an LDAP client profile is optional if it is the default setting as indicated by “man getent”. Many define the SSDs explicitly for clarity purposes.
5) The “shadow: files ldap” entry seems to be an optional entry for Solaris /etc/nsswitch.conf, but I usually put it there. For Red Hat it seems to be needed.
6) Use the sample pam.conf for pam_ldap provided by Solaris10 system admin guide with all “pam_unix_cred.so.1” lines commented out, this version works for telnet/ftp/su/sshd w.r.t. LDAP authentication.