Lecture 17 — Java EE (Java EE) Overview
Most real world applications need access to central resources, such as up-to-date inventory, available seats on a plane, highest bid to date on an auction item, etc. Often these resources are stored on a database, but other resources are accessed centrally too: current stock prices, credit-card processing, inventory adjustment, etc. This implies the client is remote from these resources, and must use a network connection to access them.
Instead of having smart clients installed remotely (so-called thick clients), application servers install the client code centrally, along with the other resources. Users can then use a much simpler client to connect to the application server. Often just a web browser is used, but other so-called thin clients can be used as well.
Such networked applications are known as enterprise applications, or web applications when the client is just a web browser. These often have different requirements (scalability, use in a cluster, reliability, etc.) than simple, stand-alone applications. While you could code up enterprise applications in standard Java, it would be like coding your own version of the Oracle relational database for each application. It is much easier to let some vendor code up all that infrastructure, called a framework or sometimes middleware. Then you just use the framework for DB access, network (including HTML) access, transactions, messaging, etc.
To avoid having each vendor have incompatible frameworks, the Java EE specification defines the interface for these features. To use Java EE, you need some vendor’s server that implements some or all of these interfaces. For example, you use the standard Java EE API to send email, but you still need some vendor’s server that implements that API. Note you can change vendors without changing your code, since the API is standard.
The Java EE server is called a container, probably because it contains Java EE applications. A servlet container (or web container) such as Tomcat only implements some of the Java EE specification. An EJB container such as Glassfish implements the complete Java EE specification.
The server provides many services to your Java EE applications, and can even automatically inject code into the server-managed components of your application, which can simplify your code by eliminating a lot of “boilerplate” code. (However, the hidden nature of the code injected can lead to confusion when reading and debugging your application code.)
You simply code up your applications normally, making sure the appropriate jar file(s) from the vendor are on your CLASSPATH. Some servers are free, such as Tomcat (which only implements a subset of the Java EE standard) and Glassfish. The tricky part is adding your code to the vendor’s server, known as deployment. Details of deployment vary between vendors, although some parts are standardized in Java EE. To help with deployment, many IDEs (such as NetBeans) include automatic deployment, if you install them with a server. A more popular approach, not requiring some GUI IDE, is to use Apache Maven.
The original Java EE spec, known as Java EE, left much to be desired. Many additional frameworks have been developed to fill in the gaps or provide simpler APIs. But Java EE keeps evolving, taking the best ideas from those other frameworks, and including them in Java EE. Version 6 is considered pretty good all by itself.
Learning Java EE means learning the new concepts and APIs to use. There is a lot to learn, including handling HTTP requests, producing HTML output from Java, Using the new persistence model to query and update the database (SQL is not needed), Creating and using transactions, sending and receiving messages and email, finding resources on the network, and so on. It is usually best to start small, learning one new technology at a time. (This is why Tomcat is popular; it handles a useful but simple subset of Java EE.)
Because of the many additional concepts and APIs, Sun (and now Oracle) provides additional training and certification for Java EE developers. Starting in 10/2011, Oracle introduced a new, mandatory training requirement for anyone interested in pursuing the highly coveted architect designation. Formerly known as the Sun Certified Enterprise Architect (SCEA), the newly branded Oracle Certified Master, Java EE 5 Enterprise Architect examination requires candidates to complete a multiple choice exam, submit an enterprise design project, and complete a proctored essay exam. Candidates must also take one of a half dozen topical courses offered by Oracle before the architect credential is granted.
The really, really, brief version:
Java EE is mostly about creating web applications, the scalable and distributed servicing of requests from clients. That usually means separating the user interface code (the web tier) from the rest of the code (the business tier). The core of such web apps is the Servlet API in the web tier, and session beans and message-driven beans in the business tier.
So Java EE is basically all about applications where a client is expected to use a web browser to access a web app. This means creating an app that handles HTTP/HTTPS requests from web browsers, or SOAP (XML) requests coming in over HTTP/HTTPS for a Java web service (to support SOA). The other aspects of enterprise applications are messaging (JMS, or Java Message Service), and talking to a database (EIS tier, using the connector part of Java EE).
In a Java EE application, you don’t write the low-level Java code to do all that. An application server provides those services to your app, and you just need to “plug-in” your code, by providing the classes and methods the application server will invoke when clients make requests. There are many application servers that meet Java EE specifications (so your code will plug-in without problems), including Glassfish, JBoss, Geronimo, and some commercial ones. (But, you need to check the version of Java EE each is compatible with!)
In addition, there are scaled-down application servers that implement a subset of the Java EE specification, the most popular being Apache Tomcat. (Tomcat is often used as the heart of other app servers, including some of the ones mentioned above.)
Java EE started as a very low-level API with many important parts missing, and other parts very badly designed. There are large differences between the original Java EE, Java EE 3, 4, 5, and the current version, 6. If at all possible, avoid all older versions and any old books.
In addition to the standard Java EE interfaces, there are a number of available frameworks that aim to simplify one or another aspect of creating web apps in Java. Such frameworks are a wrapper around one or more of the standard Java EE interfaces, with a (hopefully) simpler interface. Struts, Wicket, Tapestry, and the core technology “Java Server Faces” (JSF), are web-tier frameworks that aim to simplify processing of requests. They all support MVC. Technologies like JSP and Facelets are view technologies, and are used by these web frameworks (or you can use them directly) to provide a Java way to create HTML web pages automatically.
Other frameworks are designed to help with persistent data (the database, or EIS tier): JPA (Java Persistence API) is an API that is equally applicable to desktop Java or enterprise Java. It’s an API for object-relational mapping (ORM), and combines lessons learned from popular (and not-so-popular) ORMs like JDO, Hibernate, Toplink, and others. Using this means avoiding the low-level JDBC API. Java EE even includes a query language so you don’t need to use SQL (and the results are collections of objects).
(“Spring” is a collection of frameworks you may hear about, designed by those who hated Java EE. Java EE 6 is so much better now, that you probably won’t need any part of the Spring frameworks.)
Learning Java EE and the related web, XML, database, and other technologies will take years, so don’t expect to understand it fully at first. Start with the Java EE tutorial (currently for version 6).
It is possible to write a Java application access such resources on the local computer. But in the real world, such central resources are on a different host. Also, some parts of the application may run on a different machine than other parts, and they still need to communicate. We can write code that uses networking APIs to contact these central resources. What’s wrong with that?
· Every change to the central resources will require every copy of the application to be updated. Customers don’t like frequent updates, and if they don’t update and the application fails, they will go to your competitor.
· By allowing remote applications to access your precious resources, all sorts of security problems can arise, including unauthorized use and denial of service.
· A remote application will need to read the central resources every time, from the network. It is usually not feasible to cache this on each and every client. So frequently access information, such as a catalog, will be slow to access. If you do cache information you risk it going stale (out of date), unless you check for changes frequently. No matter how you look at it, your central resources will have lots of network traffic to contend with. Network bandwidth is expensive.
· With remote applications doing all the work, logging and auditing become impossible: If something doesn’t work right you won’t know until the customer complains. You will not have a complete audit trail for legal and financial purposes. (Imagine a customer buys something, the credit card service is contacted directly and the customer billed, but the network connection back to your database fails and the order isn’t completed!)
One simple way around this is to keep the application with the central resources, and only have a remote user interface. This is called client-server computing and it works very well. This scheme is been in use for over 20 years. Since some of the application is in one place and other parts are elsewhere, this is also called distributed computing, enterprise computing, or other terms depending on who you ask.
Definition of Terms for Enterprise Computing (from Sun’s Java Enterprise Cert)
· Scalability – ability to support the required quality of service as the load increases
· Reliability – the assurance of the integrity and consistency of the application and all of its transactions. Reliability spans from the OS to the application, to the service provided.
· Availability – the assurance that a service/resource is always accessible
· Maintainability – the ability to correct flaws in the existing functionality without impacting other components/systems
· Extensibility – the ability to add/modify additional functionality without impacting existing functionality
· Manageability – the ability to manage the system in order to ensure the continued health of a system with respect to scalability, reliability, availability, performance, and security.
SOA and RESTful Web Services
Service-Oriented Architectures (SOA) provide a mechanism for very different systems to work with one another, even across programming languages and platforms. The basic concept is that if you have a proprietary system or a system with which you want other systems to interact, it is better to place a service in front of that system and then allow your other systems to interact with the service rather than directly with the destination system.
While SOA defines the architectural concepts, it does not specify the implementation details. That’s where web services come in: web services are an SOA implementation. In the early days of web services, the majority of communication was performed using the Simple Object Access Protocol (SOAP), which defined a standard XML-based document format with applications could communicate. (SOAP was designed to replace the never popular CORBA standards.) SOAP evolved to be a very rich document format that allows you to transport data from one system to another and to invoke commands on a remote server; in the process of evolving it was no longer “simple”.
The concept behind REST (Representational State Transfer) services is that a service exposes the state of its resources. For example, the service may be a music store that exposes its music library and the current stock of its items as its resources. Then diving deeper, a musical item may expose the name of the artist, album, and songs on the album, as its resources. If the client allows a user to buy an album then the client may update the quantity of the album by subtracting one. The key is to think about what you’re exposing in terms of the state of your resources, rather than as a set of operations that manipulate that state.
A RESTful web service (also called a RESTful web API) is a simple web service implemented using HTTP and the principles of REST. Such a web service can be thought about as a collection of resources. The definition of such a web service can be thought of as comprising three aspects:
· The base URI for the web service, such as http://example.com/resources/
· The MIME type of the data supported by the web service. This is often JSON, XML or YAML but can be any other valid MIME type.
· The set of operations supported by the web service using HTTP methods (e.g., GET (fetch some data item, or a whole collection), PUT or POST (create new or update an item or whole collection), and DELETE).
Here is an example RESTful web services call to the Google Maps GeoCoder service, for the White House:
http://maps.google.com/maps/geo?q=1600+Pennsylvania+Ave,Washington,DC& output=xml&sensor=false&key=mykey
And the response looks like the following:
<?xml version="1.0" encoding="UTF-8" ?>
<kml xmlns="http://earth.google.com/kml/2.0"><Response>
<name>1600 Pennsylvania Ave,Washington,DC</name>
<Status>
<code>200</code>
<request>geocode</request>
</Status>
<Placemark id="p1">
<address>The White House, Washington, DC 20500, USA</address>
<AddressDetails Accuracy="9" xmlns="urn:oasis:names:tc:ciq:xsdschema:xAL:2.0">
<Country><CountryNameCode>US</CountryNameCode><CountryName>USA</CountryName>
<AdministrativeArea><AdministrativeAreaName>DC</AdministrativeAreaName><SubAdministrativeArea>
<SubAdministrativeAreaName>District of Columbia</SubAdministrativeAreaName><Locality>
<LocalityName>Washington</LocalityName><PostalCode><PostalCodeNumber>20500</PostalCodeNumber>
</PostalCode><AddressLine>The White House</AddressLine></Locality></SubAdministrativeArea>
</AdministrativeArea></Country></AddressDetails>
<ExtendedData>
<LatLonBox north="38.9062952" south="38.8889273" east="-77.0203584" west="-77.0523732" />
</ExtendedData>
<Point><coordinates>-77.0363658,38.8976118,0</coordinates></Point>
</Placemark>
</Response></kml>
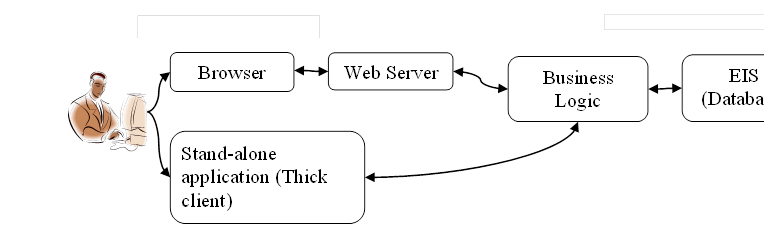
Client server computing
Client server systems come in different configurations:
· Thick (fat) client — A standard (or web-start) Java application or applet that communicates across a network to the server. The client is the user interface or presentation layer or tier. Such systems can use different approaches to networking: using TCP/IP and define a custom protocol for the application, use HTTP GET and POST protocols to pass messages and data, use SOAP ( See SOA=service oriented architecture, WSDL (Web Service Description Language), UDDI, apache AXIS for Java SOAP to pass objects back and forth, and others too.
With a fat client, most if not all the work is done at the client. This design requires large executables to be downloaded. Updates require another d/l. The server (if any) only provides a central storage place with very little business logic.
· Chubby client — all the grunt work (SQL etc.) is done on the server along with all the business logic. However the client has a lot of (JavaScript) code which runs to provide the user with a “rich experience”. This code is reloaded every time it changes with no interaction by the user. AJAX (and Web 2.0) falls into this category.
· Thin client — A web browser talks to a web server, which presents a form typically using JSP or servlet technology. (Of course, PHP and ASP pages could be used too, but in this course, we will stick to learning only one language, Java, to keep the amount of languages a developer needs to master to a minimum.) Note the client in this case is the JSP/servlet web server code. This can get confusing (the client of the server is on a web server). This is how most web pages currently work.
The thick client has the advantage of a rich and fast user interface, that can include extra features such as caching. Also a thick client can operate even if the Internet connection is unavailable (common for mobile users), and in any case appears much more responsive (no network latency for updates). However, the thick client has many of the same problems (especially deployment and security) that plague stand-alone (non-client-server) applications. Java WebStart is an attempt to mitigate this problem but is not widely used today.
The thin client is limited to what a web browser will show. This can be more difficult as a good-looking web page requires use of HTML/XML, JavaScript, and CSS. Worse, there are browser compatibility issues so some page may not look good on some older, different, newer, or different platform web browser unless you go for dull, boring user interfaces. Still, this approach does keep everything in one place, so no deployment and few security issues arise. Because the processing is done on a server, the user experience may be slower than with a thick client. If the Internet is unavailable, the thin client fails to work at all. The thin client also needs to worry about issues such as the back button, and multiple browser windows open at once.
Today the thin client is the preference of many developers especially with AJAX which provides some thick client benefits. However, this changes over time as more powerful laptops with more RAM become popular, more different web browsers become incompatible, and networks become more or less reliable and secure.
Either way the client must communicate with the server. Often this is with RMI or other means such as CORBA or even very low-level sockets. (CORBA was supposed to do this but ended up too complex and although Java supports this it is not often used. This situation may be changing though. Sockets is too low a level to develop significant distributed applications with.)
Multi-Layer or Multi-tier Design
The client talks to your application on the server, which access the central resources. There are different types of resources, and even from the same type (such as a database), there are different vendors. Often you need to access mainframes (yes these are used in the world!) or legacy systems running proprietary software that can’t be easily (or at all) updated. (Even if you don’t need that now, your application may need to support this someday!)
Such resources are known as Enterprise Information Systems or EIS. It has been found to be a generally useful thing to split your application into several parts:
· Presentation layer (or tier) - Separating the client code from the rest means you can have different sorts of clients for the same application: a web interface, a standalone (or WebStart) application, or even an applet. Also you can have designers make functional and attractive UIs, and developers (with little artistic talent) work on the logic of the application. With Java EE 5 a framework called Java Server Faces (JSF) is used to develop the UI for a Java EE application. Often a web interface is developed on JSF that uses another standard technology, servlets and Java Server Pages (JSPs).
· Business logic (BL) layer (or tier) - This is the meat of your application. The client (presentation layer or tier) code talks to this code. In Java terms, the client will create objects of these classes and invoke their methods; the results are then formatted and displayed to the user.
· Data access and integration layer (or tier) - This is the code that talks to the EIS components. This code hides the messy details from your nice simple business layer code. The code in the business layer will invoke methods of objects in this layer. This layer can also be known as the EIS layer or tier.
Here’s an example: The user clicks a link on a web page to view their current balance (before they get to this page assume they logged in somehow). The link (which may be a form’s submit button or just a link) sends the request to the client, typically a servlet. The servlet in turn invokes the business logic code to get the client’s payment information, then requests the amount of outstanding orders, and adds all that up and returns the data to the presentation layer, which formats it as HTML. The business logic methods don’t invoke JDBC or networking API directly, rather they invoke methods in the data access and integration layer. This code contains the JDBC and SQL or other code to get the information from the EIS (say the Visa interface to the bank, PayPal, or we track it ourselves in a database).
There are many different ways to organize this code. The common way is to use JPA entities (previously, Enterprise JavaBeans (EJBs)) in the EIS and BL layers, but of course, it may be better to use a different technology or organization in any given case. Knowing when to use which technology needs a lot of background knowledge and experience, which is why enterprise computing is so hard to learn!
Scalability, Reliability, and Availability
You won’t get a lot of business done with a single client talking to a single server. In some large-scale systems, it is hard to predict the number and behavior of end users.
Scalability refers to a system’s ability to support fast increasing numbers of users. [From Wikipedia:] Scalability is a desirable property of a system, a network, or a process, which indicates its ability to either handle growing amounts of work in a graceful manner, or to be readily enlarged. For example, it can refer to the capability of a system to increase total throughput under an increased load when resources (typically hardware) are added.
The intuitive way to scale up the number of concurrent sessions handled by a server is to add resources (memory, CPU or hard disk) to it. To scale vertically (or scale up) means to add resources to a single node in a system. This typically involves the addition of CPUs or memory to a single computer. Such vertical scaling of existing systems also enables them to leverage virtualization technology more effectively, as it provides more resources for the hosted set of operating systems and application modules to share.
Vertical scaling has limits. You typically run one JVM per server, with many threads (one per request). However this design only scales up to one to four thousand concurrent requests, no matter how many CPUs are available. Also, 32-bit systems cannot use more the 2GB of RAM per process (per JVM). Tasks that use I/O heavily can only use so much CPU power; the bottleneck becomes the IO. Running multiple JVMs per server is possible to make use of additional RAM but leads to other problems, such as resource sharing, singletons, synchronization, etc.
To scale horizontally (or scale out) means to add more nodes to a system, such as adding a new computer to a distributed software application. An example might be scaling out from one web server system to three. As computer prices drop and performance continues to increase, low cost commodity systems can be used for high performance computing applications such as seismic analysis and biotechnology workloads that could in the past only be handled by supercomputers. Hundreds of small computers may be configured in a cluster to obtain aggregate computing power which often exceeds that of traditional RISC processor based scientific computers.
Clustering or grid computing are horizontal scaling alternatives that allow a group of servers to share tasks and operate as a single server logically, enabling the system to serve multiple clients at the same time.
Note you may have a cluster of web servers and a single application server, a single web server and a cluster of application servers, or (independent) clusters of each.
This approach requires middleware, software that can direct incoming requests from users to available thin clients, and route thin client requests to available servers. This is called load balancing. A good load balancer/middleware is very complex and most people buy these instead of writing their own. A server running middleware, which in turn invokes your application code, is called an application server.
A typical picture of an enterprise application cluster looks like this:
Clustering is a popular technology that provides highly available and scalable services, with fault tolerance. The lack of details in the Java EE specification means different vendors implement clustering differently. Some popular products include the BIG-IP™ load balancer from F5.com. Tangosol’s Coherence™ provides a distributed data management platform, which can be embedded into most popular Java EE containers to provide clustering environment. Coherence also provides distributed cache system which can share java objects among different JVM instances effectively. See www.tangosol.com/. Other solutions include Terracotta DSO and JavaSpaces.
Additionally a single-server solution (add memory and CPU) for scalability is not robust due to a single point of failure. Mission-critical applications such as banking, billing, medical systems, etc., cannot tolerate any service outages. These services must always be accessible with reasonable and predictable response times. Clustering is a solution to achieve this kind of high availability by providing redundant servers in the cluster in case one server fails to provide service.
Clustering in the Web tier is the most important and fundamental type of clustering. Web clustering technique includes web server load balancing and HTTP Session failover.
“JavaGroups” is currently the communication layer of JBoss and Tomcat clustering, and provides core features such as “Group membership protocols” and “message multicast”, which are very useful in making clustering work. For more information about JavaGroups see jgroups.org.
Another scalability problem is usually the Database management system. This is the most common bottleneck for most of enterprise applications, since the database is normally shared by the JVM threads. So effectiveness of database access, and the isolation levels between database transactions, will affect the scalability significantly. Once possibility is to put most of the business logic resides in the database, using stored procedures, while keeping the Web tier very lightweight, just to perform simple data filtering actions and process the stored procedures in database. However, this architecture is causes a lot of issues with respect to scalability as the number of requests grow.
Question: What issues arise with a clustered design that you don’t have with a simple application? [Adopted in part from “Mastering Enterprise JavaBeans” by Ed roman, et. al., (c) by Wiley.]
· Remote method Invocation (RMI), so client code can call server code.
· Load balancing. This is one of the key technologies behind clustering, which obtains high availability and performance by dispatching incoming requests to different servers. The middleware must be able to know if some application server is busy and direct the client request onto a different application server.
A load balancer could be a hardware product with SSL accelerators such as the F5 Load Balancer, or just another web server with load balancing plug-ins. Even a simple Linux box with iptables (packet filter firewall) can load balance very well.
Dispatching can be implemented with round-robin, random, source-IP based, or work load based algorithms.
In addition to dispatching requests a load balancer should perform some other important tasks such as “session stickiness” to have a user session live entirely on one server and “health check” (or heartbeat) to prevent dispatching requests to a failing server. Sometimes the load balancer will participant in the Failover process (see below).
· What if a web or application server crashes? The middleware must be able to restart (or at least back out of) any transaction and user sessions with a different server. This is known as transparent fall-over. There is usually a time delay associated with this in seconds (could be minutes if this feature isn’t carefully designed). Note that data corruption must be avoided even if a server fails in the middle of a session; this is called fault tolerance.
· Transaction processing. If you use files or lightweight databases, you need to worry that two or more sessions might simultaneously access the same piece of data. Even with powerful back-end databases you need to be careful. This is because DBs use connections to separate transactions, and as these are slow to setup, you normally use a technique known as resource pooling to reuse connections. Also, the user session might start on one application server (using one DB connection) and finish on another (using a different DB connection).
· Application server state. Ideally all persistent information is stored in the EIS so nothing is lost if the session moves to a different server (for instance when one server crashes). However this design is slow and causes a lot of network traffic to the EIS resources. So, if you store some information on the application server, does it need to be copied (replicated) on all servers? When a server restarts, how is that information loaded/initialized?
Just about every web based application has some session state, such as remembering whether you are logged in or the contents of your shopping cart. Because the HTTP protocol is itself stateless session state needs to be stored somewhere and associated with your browsing session in a way that can be easily retrieved the next time you request a page from the same web application. This can be done in several ways; the best is to store a session “cookie” on the browser. This cookie is sent to the server with every HTTP request. A session cookie expires when the browser session terminates (that is when the browser closes). Also the servlet container (web server) can associate a timeout for sessions.
When a browser visits a stateful web application this application creates a session object in memory to store information for later use. It sends the browser a globally unique HTTPSession ID cookie which can identify this session object in the cluster. There are methods to add and access data in a session object.
Other options include using complex and long URLs that contain session information, or hidden form fields.
Note the problem of load balancing and fail-over with session data; if the session can be dispatched to a different server next, where is the session data kept? The middleware must make one or more copies of the session objects on different servers, and keep them synchronized as changes occur. (Using the EIS DB is simple by very slow.) Tomcat 5 copies all session objects to all servers on all updates. JBoss and other servlet containers follow a more efficient approach of paired servers or paired sessions, so each session object is backed up onto one other server. IBM’s Websphere uses a special high-speed central DB for sessions.
No matter what the choice you may need to configure (“tune”) the frequency of session replication, and the granularity (whole session or just the modified bits).
· Deployment. How can you cleanly update your application code an all the servers without stopping all of them at once?
· Clean shutdown of application server. When a server must be stopped for updates or other maintenance, you don’t want to abort the currently running sessions.
· Logging and auditing. You need a central log for determining if problems exist (and if so, what went wrong), and for auditing (information about what was done, by whom, and when). Auditing is required (compliance) by various legal, accounting, and regulatory bodies (FBI, SEC, FTC, ...). Be careful about logging user identification data: don’t log if possible, else use data blinding (substitute user IDs with unique random strings: you can still relate all messages to that user but don’t know which user it is). Use encryption to protect logs from modification (digital signature per entry, plus manager sig: dual controls) and access.
· Systems management (IT). Who gets paged (and how) when a problem occurs, or in the event of a disaster (power loss, fire, ...)?
· Distributed applications. One object’s methods may invoke another object’s methods. With distributed applications, the second object may be loaded in the same JVM, on the same server but loaded by a different JVM, or loaded on a different server (and thus a different JVM). So, how do you make sure to not load the same class twice? What happens if two copies of some class are loaded (and you change static properties), or you create too many copies of some object (e.g., a DB connection to your Oracle server)? Given the many different vendors of application servers, where are your classes put so that the JVM classloader can find them? (This is why you often use a custom ClassLoader.)
· Multi-threading issues. Since each web server will likely have to handle several user sessions, and will each application server, you need to support multi-processing or multi-threading.
· Support message oriented middleware. Some EIS are web services that you talk to, not by RMI or by some proprietary network protocol, but by passing (simple) messages back and forth.
· Resource pooling. The obvious candidate is database connection pooling, but other resource that take time to setup and initialize, and to tear down when done, can often benefit from having a bunch of such resources pre-created in a pool (a collection of some kind), ready to go. When you need (for instance) to send a SQL query to the database, you grab a pre-built connection from the pool, pass it the SQL code, and run it. After the connection returns the results, you clean up the connection and return it to the pool.
· Security. You must validate all user input and sanitize it (SQL/XML injection, XSS): be careful of HTML constructs such as “<”, “&”, “>”, other illegal characters, length restrictions, numerical limits, etc. User data used for filenames has extra restrictions: “..”, “/” and “\”, etc. Validate everything, not just user input fields but cookies and all data. After a user has been validated, issue a new session ID. Invalidate session IDs at logout (or after timeout). Use a quality source of random numbers (i.e., have a large entropy pool). Avoid native methods (no security). Store sensitive data (credentials) security encoded, even in RAM. Hide all low-level error messages from user (show only generic message, ok to log full message.) Mark all scaffolding/testing code with annotation, to easily find and remove before production release. Use BigInteger/BigDecimal to convert string input data to numbers, then check limits before converting to int/float so no over/underflow errors.
· Caching. All sorts of data are frequently needed by applications. It makes sense to have copies on each server for quick access. But these caches need to be updated when the data in the EIS changes.
· Business tier object management (lifecycle). These objects need to be created when the client makes a request and/or a session is started. They need to be destroyed when no longer needed.
· Persistence of objects. An object representing some user’s shopping cart needs to persist for a long time (minutes). What happens if the application is restarted on a different server, or if the server crashes? Such objects need to be persistent. You could of course write your business logic so that every change by the user is immediately sent to the database, but such a design causes way too many database connections! If too many users try to use your system at once you will overwhelm your DB and/or network, and it may cause data loss, dropped sessions, or crashed DB or servers.
Another problem is exactly how to store objects into relational database tables (known as O/R Mapping, or object/relational mapping). With Java EE 5 and newer, JPA (Java Persistence API) does this. You only need to define objects, then run an SQL-like query language to populate the fields of these objects or to store any changes made back to the DB. (Of course someplace you need to define the DB, username, password, and other connection information.)
A common question is why bother using all this ORM stuff if you
already know SQL? One reason is the SQL isn’t portable; it isn’t really
standardized except for the most basic uses. Using some ORM also gives you:
- caching (first level & second level)
- lazy loading of related objects
- transaction support (EJB, transaction context propagation)
- better/cleaner query language
- fetching of related objects in a join, good for performance
But, many expensive DBMSs offer useful features not available if using ORM, such as fine-grained access control, hierarchical queries, triggers, stored procedures, and Analytic Functions. However, most ORMs allow one to mix in SQL when needed.
On any project you must weigh factors such as portability, need for advanced features, local expertise, and ease of development.
A number of technologies for this are available: JDBC (no mapping, straight SQL), JDO (mostly a dead project now), Entity EJB (either bean-managed persistence, BMP, or container managed persistence, CMP), JPA (replaces Entity EJBs), Hibernate, Oracle Toplink, and others. Each has unique strengths and weaknesses, so there is no one best solution.
Example of JPA code:
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity public class Customer {
@Id private Long id;
private String firstname; private String lastname;
private String telephone; private String email;
private Integer age;
// constuctors, getters, setters
}
//...
@PersistenceContext(unitName="MyDB")
EntityManager em;
Employee emp = new Employee(...);
emp.setName("Miller");
em.persist(emp);
// ...
Employee emp = em.find(Employee.class, "Miller");
emp.setAge( new Integer(21) ); // DB updates automatically!
// ...
if (emp != null) em.remove(emp);
The EntityManager takes a parameter that refers to a specific persistence unit (“MyDB” in the code above). Persistence units are declared in the standard persistence.xml file, and contain information such as the database to use, the JDBC driver, and any implementation-specific properties. Note the table and column names are automatically derived from the Customer class (but may easily be over-ridden if desired).
· Naming services. In a clustered environment, how do different objects find each other? How does the client “know” where to find the server? How does the various business logic objects “know” which EIS to use and how to contact it? How do you refer to some EJB or other object, when that object may not be loaded in the local JVM but rather some other server’s JVM? An analogy is “how does a web browser know where some website such as www.wpollock.com is?”
The obvious answer is to hard-code that information everywhere. Then when your DB changes it IP address you have to re-write and then deploy all new versions of your application. Not a good idea! The answer is a name-to-resource database (just like a browser uses DNS to translate a name “wpollock.com” to an IP address.) Your objects can “lookup” some resource by name, and then use the returned information to access that resource. This is the JNDI API. Note some servers don’t use a global (cluster-wide) JNDI DB but rather one per server (Sun and IBM). However these use special agent software to achieve the same effect.
Enterprise applications are often quite large: either a large number of users (so performance matters), a large geographical area, a large amount of data to organize, or some combination of these factors. Such applications end up as very large applications (in terms of code size). Because of the size it is quite common to purchase some parts “off the shelf” from vendors such as Sun, IBM, BEA, Oracle, etc. This is true of the middleware, load balancing, web servers, backend databases, and especially common application services (transactions, persistence, logging, creation/destruction of business objections, ...). Other parts (the presentation web pages/forms/servlets/JSPs, business logic, and sometimes EIS tier code) will be developed by independent (teams of) programmers.
Many of the issues above (and may others) are common enough that a market was created for “application servers”, systems that included middleware and support for persistence of objects, transactions, load balancing, systems management, etc. To date there have been about 50 such products you can purchase. In the past, every one of these application servers had proprietary interfaces. So your business logic classes (and other code) had to be written for one specific brand of application server, or you had to do all that code yourself. If you picked the wrong company or product, you probably would need to start the application over nearly from scratch.
The answer to the need for off-the-shelf services that don’t have proprietary specifications and interfaces is Java EE. Java EE is a specification, not a product. So if the database product you bought yesterday is Java EE compliant you can be confident it will work with the Java EE application server you buy tomorrow. And if you develop Java EE business logic components (sets of classes), you know they can be deployed without change in any Java EE compliant application server (assuming the same Java EE version, of course).
Some of the most common Java EE specifications include EJBs (Enterprise Java Beans), servlets, JSPs (Java server pages), JDBC, JavaMail, JMS (Java Management Services), etc. Often the data is passed around using XML. Security technologies such as user authentication and data encryption (and IPsec for network security) are common.
Containers are standardized runtime environments that provide specific services to components. Components can expect these services to be available on any Java EE platform from any vendor. Thus we talk about servlet (or web) containers, or full Java EE containers (usually referred to as EJB containers).
EJBs come in three different types: session beans, entity beans (now replaced with JPA), and message beans. Note an EJB is different from a JavaBean. Not all applications use all types of EJBs but session beans are common.
Because the business logic deployed in an application server is so often a set of EJBs, an application server compliant with Java EE is also called an EJB container. (Similarly, web server part of the client code is often deployed in a Web application container or servlet container, which is just a web server that knows about servlets, JSPs, and WARs.) The client computer where application code runs (especially for thick clients) is sometimes referred to as a application container.
A typical enterprise application is used this way: a user connects to the client part of an enterprise application, starting a session. The client is often implemented as part of a web server with a servlet or JSP page. Once the session is established the client and application exchange messages or even objects (which are serialized and send as regular messages) using XML and HTTP or other network protocols. The application often gets data from other servers, perhaps a central database server. Updates (orders, reservations, ...) are handled with transaction management. When finished the session is terminated (or times out).
To fully understand enterprise applications (well enough to design them properly) you need to master many technologies including web server technology, database technology, networking technology, security technology, multithreading/clustering (for high volume and good performance), and others too. Security and encryption technology should also be understood. You don’t have to be able to write code for all these technologies but you need to know enough to decide which technologies you need for a given application, how to buy a product with the required features, and how to write a bit of “glue” code to tie the different pieces together.
Sun also provides a series of classes that can be used to implement parts of a Java EE enterprise application (such as JDBC to talk to legacy databases using SQL, messaging interfaces, etc.), as well as other useful bits such as deployment tools.
A competing technology is the .NET series of standards from Microsoft. But these are not being widely adopted (at least not yet outside of MS).
Java EE Development Issues
One problem today is that the Internet is a hostile place. The data must be encrypted when send and the sender (and recipient) must be verified using special security methods. Since many parts of the Internet are protected by firewalls today, many enterprise applications with thick clients use port 80 (the standard web server access) port to go through the firewalls. This creates additional security problems.
Another problem is that not all parts of an enterprise application are standardized through Java EE. A common example is the configuration of the application server or web server. Newer editions of the Java EE standard provide the standards, tools, and Java classes help solve these problems.
In spite of all the care that makes Java EE applications work on nearly any server, some of the APIs used are “low-level”: full of messy details that are difficult to make correct, efficient, or both, or are just plain repetitive and boring for most programmers. To help with this a number of technologies were created, not really part of the Java EE standard but built on top of these APIs and specifications, that are at a “higher” level and hopefully easier to learn, use, and reuse. These are called Frameworks. Examples include Struts, JavaFaces, and Apache Tapestry, to simplify the web/presentation layer development for user interfaces (so you can avoid servlets and non-standard custom JSP tag libraries); Hibernate, JDO, and others to manage persistent data (so you can avoid JDBC; however there is now the JPA or Java persistence architecture so these frameworks are less needed), Spring and seam to simplify overall Java EE development (especially of CRUD—Create, read, update, delete—apps), and others such as AspectJ (See Wikipedia for this). Other frameworks include JBI (servicemix.org) and RAILs (for Ruby). (Rails doesn’t scale to clusters though, all state in in a single DB.)
Design pattern such as “Singleton” use static variables to share a state among many objects. For example tracking the number of users. Using static variables works well on a single server but fails in a cluster. Each instance in the cluster would maintain its own copy of the static variable in its own JVM instance, thereby breaking the mechanism of the singleton pattern. A preferable way in a cluster is to store all state data to a database.
Caching state is a big problem. Putting all state in the backend DB works but can be very slow. Storing some state in the presentation or application tier can greatly enhance performance, but stateful session beans cause a lot of trouble with clustering, failover, performance (the non-functional requirements, or NFRs). One technique is only use stateless session beans, and hold any session state in the servlet containers (the presentation tier). Another is to replicate the state on one or more (or all) application and/or web app servers. This required more sophisticated middleware/app servers.
Similar problems arise in a cluster if you store any data in files. Besides not using files, consider a SAN (storage area network) to provide a central file service all servers share.
Remember that although there are a lot of APIs and technologies as part of Java EE, all are optional! You only use what your application needs. Usually there is more than one way to design the application too. Knowing the best (or at least a good) design takes experience.
The specific API’s mandated for Java EE 5 are:
· Enterprise JavaBeans (EJB) 3.0
· Servlet 2.4
· JavaServer Pages (JSP) 2.1
· Java Message Service (JMS) 1.1
· Java Transaction API (JTA) 1.0
· JavaMail 1.3
· JavaBeans Activation Framework 1.1
· Java EE Connector Architecture 1.5
· Web Services for Java EE 1.1
· Java API for XML-based RPC (JAX-RPC) 1.1
· Java API for XML Web Services (JAX-WS) 2.0
· Java Architecture for XML Binding (JAXB) 2.0
· SOAP with Attachments API for Java (SAAJ) 1.3
· Java API for XML Registries (JAXR) 1.0
· Java 2 Platform, Enterprise Edition Management API 1.0
· Java 2 Platform, Enterprise Edition Deployment API 1.1
· Java Authorization Service Provider Contract for Containers 1.0
· Debugging Support for Other Languages (JSR-45)
· Standard Tag Library for JavaServer Pages (JSTL) 1.1
· Web Services Metadata for the Java Platform 1.0
· JavaServer Faces 1.2 Requirements
· Common Annotations for the Java Platform 1.0
· Streaming API for XML (StAX) 1.0
· Java Persistence API 1.0
Issues for selecting Java EE application servers
Java EE branding, pluggable JRE, conversion tools (Old Java EE to new Java EE), 3rd party JDBC driver support, Lazy-loading (Load beans on-demand), deferred DB writes (don’t update the DP until commit), Data Cache (some servers us pass-through so every access results in a slow DB operation), Presentation-EJB integration (one server with one JVM doing both), scalability references, high availability, security (JAAS support), IDE, UML Editor integration, intelligent load balancing, transparent fail-over (for stateless sessions), clustering with transparent fail-over, support for optional Java EE features: Java Management Extension Java EE Connector Architecture (integration of EIS components), Hot Deployment (no reboot needed to re-deploy), EJB instance pooling and automatic generation, clean shutdown, some useful EJB components included, ...
Almost every Java EE project uses object caching to improve performance, and all popular application servers provide some type of caching. Caching is not currently part of the Java EE specs, so every vendor does this differently. Note these caches are typically designed for a standalone environment and can only work within one JVM instance.
Caching is needed because some objects are so complex that creating a new one will cost much (i.e., DB lookups across the Internet). So the server maintains a pool to reuse the object instances without further creation.
You gain performance only if the maintenance of the cache is cheaper than objects creation. In a clustered environment each JVM instance will maintain its own copy of the cache which should be synchronized with others to provide inconsistent state in all server instances. Sometimes this kind of sync will bring worse performance than not caching!
JBoss began as an open source EJB container project six years ago has become a fully certified Java EE 1.4 application server with the largest market share, competitive with proprietary Java application servers in features and quality. JBoss isn’t just a Java EE server. It has a dynamic architecture which allows one to alter the services to make Java EE work the way you want, or even throw Java EE away completely. Sun Java EE SDK contains Glassfish, another Java EE application container. Others include Resin, Geronimo, CarbonAS, Oracle’s WebLogic, and WebSphere. For learning purposes, I recommend Sun’s free glassfish. (JBoss is very popular.)
Perhaps the most important aspect of clustering is memory replication. In memory replication, information about the state of user sessions with deployed applications in a server instance is replicated to a peer instance in the cluster. With the glassfish v2 Java EE container, each instance in a cluster sends session-state information to the next instance in the cluster, its replication partner. The order of instances in a cluster is based on the names of the instances. As the session-state information for a deployed application is updated in any instance, it is replicated around the cluster.
Glassfish also has a load balancer plug-in. The load balancer is responsible for distributing workload among multiple server instances. It also takes part in rerouting a session when an instance fails. If a GlassFish instance in a cluster fails, the load balancer reroutes the sessions interacting with that instance to another instance in the cluster.
Java Management Extensions
[ From: http://www.theserverside.com/articles/article.tss?l=JMXWebApps ]
The Java Management Extensions (JMX) standard provides a standard for the management of applications, as well as application servers and other infrastructure software. The point of this is to improve productivity of your support (and development) staff, and to improve efficiency (reducing downtime of servers, and other efficiency measures). JMX makes it possible to manage and monitor applications using a choice of management systems and consoles, including SNMP (simple network management protocol, a common standard) consoles. It also simplifies the task of making applications manageable, i.e. management instrumentation, and enables improved management of deployed applications in the enterprise. JMX provides a lot of management value with little effort.
While management tasks should be part of the design requirements, it isn’t always possible to anticipate these needs. It’s hard to change the application software at that point. This is where business-specific application management can be very useful.
The first step in managing applications is monitoring availability and performance. In order to minimize downtime and avoid disruption to business operations, you must monitor and measure the availability of applications (and their servers). Also the performance of the application needs to be tracked. This ensures the application performs to the service levels needed, and enables a quick response if the application is under-performing. Performance is usually measured by counting key business method invocations or user transactions, in a given interval of time (say per 5 minutes).
Beyond monitoring availability and performance, managing business-specific aspects of the application can be helpful in maximizing productivity. For example, a banking application may require the ability to monitor cash withdrawals to ensure sufficient cash at a required ATM or branch office. Another example is the need to monitor inventory levels for an on-line store. While some of these management needs may be anticipated and designed into the application, many of these needs arise from production use of the application.
Common web applications may include financial applications like banking, insurance, or brokerage applications, as well as a number of other intranet applications like HR, call-center, and other applications. All of these can benefit from management, to some degree or another. Work-flows and click-trails can be studied to make the application’s interface easier to navigate, marketing and other data can be collected to base business decisions on, inventory levels can be monitored, etc.
Here’s a simple example: an application that allows users to transfer money between accounts using a set of JSP pages. To complete the transaction, the user navigates through four pages: a start page, a select transaction details page, a confirm transaction page, and a transaction complete page.
In this example, as in many web applications, the user navigates a series of pages to accomplish a task or transaction. Depending on the application, it may be useful to know whether users are having difficulty completing these tasks. For example, if a number of users start a transaction but fail to complete it, it may indicate some work needs to be done on making navigation easier. You can use the session tracking capabilities available with JSP to track the data we need on how users are doing.
In addition to tracking user success in completing their transactions, for this specific application it may be useful to track aspects of the money transfer. For example, we may wish to send a management notification when the transfer amount exceeds a threshold.
The JMX architecture is based on a manager and agent model. The agent typically resides with the application server and provides management instrumentation, i.e. application data and control. The management console collects and presents management information from one or more agents on the network.
JMX management instrumentation is a set of Java components called MBeans. The MBean components are Java classes that fit design patterns based on the type of MBean. The defined MBean types are Standard, Dynamic, Open, and Model MBeans. JMX agent MBeans are all registered with a common MBeanServer interface, which remote management consoles access to get management information from the agent. (A bit like RMI.)
Standard MBeans provide a defined interface that follows a naming convention. The interface class is named by adding “MBean” to the name of the standard MBean class. For example if you call a standard MBean MyJspStats, then the MBean interface will need to be named MyJspStatsMBean.
Determining the size of an application (determining resources needed such as number of servers in a cluster)
You can simulate a system using queuing theory. A number of tools are available (none for free AFAIK) that allow you to adjust various parameters, such as the number of customers, time to process each session, etc., and graph the results in terms of response time and max load versus cluster size. Or you could hire a math magician to implement the queuing models and provide you with the numbers. (But playing with a GUI Java applet with Sliders and TextFields for input is more fun!)
Those numbers can be learned either by experience or by observing a similar (e.g., the current website) system and collecting statistics. (An interesting project is to write a program to parse a month’s worth of server logs, to determine number of customers number of sessions, number of page hits per session, and average length of time for each session and each page load.)
What constitutes acceptable response time varies per organization, but there are publicly available marketing results that show a page must be rendered in under X seconds or customers will go elsewhere. X is usually quoted as either 4.something or 8.something seconds.
Now, if you can get acceptable response time on a single server, then you can avoid cluster issues and the project is either small or medium. If a cluster is needed, it is large (some experienced developers might say medium or large, but if you are new to this, it is large!)
Most useful websites require persistent storage and the common solution is to use a database system. If you can get acceptable performance with a single host providing both the web service and DB service, the project is small.
Usually a separate server will be needed for each, in which case you need to deal with networking and possibly encryption (if you use credit card numbers for instance). To me, these extra dimensions make the project medium or large.
Until you gain enough experience to estimate a project’s scope on your own, one option is to hire a "mentor" consultant who has the experience and who can get you started on your project with a good estimate of the resources needed. Often this is cheaper than hiring a consultant to do the project for you.
Depending on local expertise available, a small project need not be done in Java. However medium and larger projects are often easier if done using Java EE technology, which provides a (sometimes) simpler API for the common tasks needed. Usually a servlet container will do for small and medium projects, and an EJB container will make life easier if you have a large one. Also the extra frameworks available and common (seam, struts, spring, hibernate, ...) handle these tasks at an even higher level, and in theory that makes the project more manageable.
My experience is that learning too many frameworks for your first big (medium or large) project is unlikely to save time on that project. But maybe subsequent ones. Indeed, practicing re-doing an existing website using a different framework is a good way to learn the frameworks. This may be true even (or especially) for a small site that doesn’t really need the framework.
Synchronization Issues Affecting Scalability
[http://www.theserverside.com/tt/articles/article.tss?track=NL-461&ad=664753USCA&l=ScalingYourJavaEEApplications&asrc=EM_NLN_4588276&uid=3138114]
Let’s take a real world case as an example. This is an ERP system for manufacture, when tested its performance in one of the latest CMT servers (2 CPUs, 16 cores, 128 strands), we found the CPU usage was more than 90%. This was a big surprise, because few applications can scale so well in this type of machine. Our excitement just lasted for 5 minutes before we discovered that the average response time was very high and the throughput was unbelievable low. What were these CPUs doing? Weren’t they busy? What were they busy with? Through the tracing tools in the OS, we found almost all the CPUs were doing the same thing - “HashMap.get()”, and it seemed that all CPUs were in infinite loops. Then we tested this application on diverse servers with different numbers of CPUs. The result was that the more CPUs the server has, the more chances this infinite loop would happen.
The root cause of the infinite loop is on an unprotected shared variable — a “HashMap” data structure. After added “synchronized” marker to all the access methods, everything was normal. (Sun engineers didn’t think it a bug, but rather suggested the use of “ConcurrentHashMap”. So take it into consideration when building a scalable system.)
Enterprise JavaBeans (EJBs) [Skip to Servlets]
[Adapted from “Mastering Enterprise JavaBeans” by Ed Roman et. al., Wiley pub.]
The Enterprise JavaBean (or EJB or Enterprise Bean) standard provides a component architecture for deployable server-side components. An application server can import, load, and communicate with EJBs using this standard. The EJB standard is a 500+ page PDF you can obtain from java.sun.com. It also includes a set of interfaces that components and application servers must adhere to.
EJBs are designed to communication with other software: in the presentation layer, other EJBs, Web services, and EIS layer components.
For some projects this is overkill. If your application is just a GUI to a database, or is very simple, or you need the initial system built rapidly (say as a prototype), then the three-tiered approach is not appropriate. Instead just use a two layer approach, having JSPs use simple Java classes to talk to the backend DB. However if you need to support transactions, sessions, banner ads, special services, communications with outside EIS or web services, or anticipate growth so scalability becomes very important, then EJB can be the way to go.
Types of EJBs
There are different types of beans, each used for a specific purpose. Not all types must be used in any given application. The most common are session beans. These beans model business processes and workflows (such as a user session while shopping on-line). Session beans typically do something; when your description uses a verb, think session bean. Such beans might be either stateful or stateless.
Entity beans model data, such as back accounts, items, bids, purchase orders, etc. These components perform the object/relational mapping and form the bridge between the business-logic layer and the EIS components. They are often referred to the persistence components.
Entity beans have been less commonly used because of poor performance and other problems. Many newer Java EE servers provide better support for the newer EJB standard, which is supposed to address these problems. However many replacement technologies (not part of Java EE, but supported by many application servers) have sprung up to solve this problem: Java Data Objects (JDOs), Hibernate, etc.
Entity beans may use either bean-managed or container-managed persistence.
Message-driven beans are similar to session beans in that they perform some task, but the interface is via messages passed back and forth according to some protocol.
Lecture 19 — Servlets and JSPs, WARs and EARs
JSP — Java Server Pages
When the presentation (user interface, or UI) code is for a thin client, you write a servlet to handle the HTTP methods, read the request data, and create a reply. That often means a lot of statements to produce HTML code.
Instead there is a simpler way. You could create an HTML page that contained various snippits of Java code, inside special tags. The web server processes such HTML pages by finding the Java bits and creating, then compiling a servlet for you. This special type of web server is called a servlet container. Apache Tomcat is a popular one. Many enterprise applications do not need the additional support of a full EJB container; Tomcat supports servlets and JSP pages, over HTTP or HTTPS, supports sessions automatically (with cookies), and the java used in the servlets/JSPs can use databases. So if you don’t need transaction support, messaging, etc., then a servlet container is all you need.
An HTML page may contain various special (large) tags, which contain Java code. Each chunk of code is called a scriptlet. When the JSP is first loaded, the page is parsed, the scriptlets are collected into a .java file, the .java file is compiled into a servlet .class, and thereafter using the JSP’s URL actually returns the output of the compiled servlet. It is possible to configure tomcat to pre-load JSPs, to make this process seem faster to the user. Usually files that contain JSP use the extension “.jsp” rather than “.htm” or “.html”.
JSPs often use JavaBeans (“beans”) to actually do something, such as fetch data from a database. This is handy if some tasks is too complex to be mixed in with the HTML directly. You just create a JavaBean that has methods that do what you want, and invoke them from the JSP. A special XML tag is mixed in with the HTML to indicate the use of a JavaBean. A good JavaBean can be reused in other applications.
The Java code and special tags in a JSP page is often considered part of the middle (business logic) tier and not the presentation layer (tier). However some could argue the other way around.
JSP supports a variety of other special XML tags that perform specific tasks. More recent versions of the JSP specification provide a way for users to define and use their own XML tags, which can do custom tasks. A collection of such tags is known as a taglib.
Eventually the set of standard tags for JSP was greatly expanded and organized into 4-5 standard taglibs. This collection of taglibs is called the JSP Standard Tag Library, or JSTL. This will be discussed below.
In addition to the JSTL, the 2.0 version of JSP is now available with many new features that make using JSP a lot simpler.
Java Server Faces
JSPs are simpler than creating a servlet by hand, but still require you to manually type in the HTML you want. That means you need to know both HTML and related technologies such as JavaScript, as well as Java. A “higher level” view of the web application was desired, so users could build the UI by drag-and-drop components using a tool such as NetBeans. Java Server Faces (JSF) is a framework that supports this type of development. Using JSF, you can build the user interface without typing any HTML code! The result is an XML document that looks very much like a JSP page, except all the code and the HTML itself is handled by special tags. This XML document gets converted into a servlet (often it gets converted into a JSP first, which in turn becomes a servlet).
One nice feature of JSF is that the output need not be standard HTML. However that is all that is currently supported by this framework. But someday JSF could support mobile devices or pure Java (thick) clients, and the JSP page you wrote won’t need to be changed! (Just a configuration setting someplace to say what kind of output to produce.) Also, JSF can be extended by adding new components (each with its own tag).
There are a number of tools that provide WYSIWYG GUI building tools for EE apps: JBoss Tools for Eclipse, GWT Designer (you can create cool UIs, but data-binding seems to be too complex), JSF (NetBeans no longer supports the visual web editor), ZK (supports easy data-binding and has got an Eclipse-based visual editor), Echo2, and Wicket (wicket.apache.org).
Creating JSPs
The basic HTML page “basic.htm” looks like this:
<html>
<head>
<title> Sample HTML Basic Page </title>
</head>
<body>
<h1> Sample HTML Basic Page </h1>
<p> This is a dull web page!
I have nothing more to say.
</p>
</body>
</html>
(Discuss HTML and HTTP GET and POST). Such a page contains only static data. It is possible to jazz it up with animated images, Java applets, CSS, and JavaScript. However these technologies are limited in what they can do, and all the processing is done on the client workstation (by the web browser).
To include dynamic content on the server side, you need the file to include special tags. The web server doesn’t send the page directly to the web browser in this case. Instead it reads the file itself, ignoring HTML but looking for the special tags. The server than does something for each such tag; usually this involves running some servlet code and replacing the special tag with the output of some method call. After the document has been processed it then only contains HTML (and possible CSS, JavaScript, ...). It is then sent to the client.
The server uses the file extension to determine how to process the file. It might use PHP, ASP, JSP, or other special processors depending on the type of file. These all work the same way, looking for special non-HTML tags and replacing them with some other HTML. (Some documents today are not HTML at all, but a related technology of xHTML or even XML. Still the special processor doesn’t care.)
The simplest JSP tag contains a legal Java expression. The tag will be replaced with the result of the expression evaluation. Here are a couple of examples:
A simple JSP page “basic1.jsp” looks like this:
<html>
<head>
<title> Sample JSP Basic Page </title>
</head>
<body>
<h1> Sample HTML Basic Page </h1>
<p> This is a dynamic web page!
The current time
is <%= new java.util.Date() %>. Hit
refresh/reload to see the time update.
</p>
</body>
</html>
The “<%= expression %>” tag can be used for any valid Java expression, such as “2+2”, “StockQuote.getPrice("IBM")”, etc. The result is always converted to a string and inserted in place of the tag.
The special tags don’t have to fit all on one line. They can appear anywhere, even inside of HTML tag attributes or inside quotes.
To deploy basic1.jsp you must be using a JSP-aware web server, sometimes called a “JSP container” or “servlet container” or “Web Application Container”. Apache Tomcat is often used for this. Your web content (including non-JSP files too) must be placed in a directory named for the web application, and placed within the server’s “deployment” location, say “server‑install‑directory/webapps/MyApp/basic1.jsp”. Then you start the server and use the proper URL to get there. For a locally installed Tomcat server with default settings, this would be "http://localhost:8080/MyApp/basic1.jsp”.
Note a web application requires special files and sub-directories too. The whole set of files is often put into a single jar file called a web archive or WAR. A WAR is standard, so any servlet container can use any WAR file. Most work like Tomcat, you simply have to place the WAR file in the correct directory.
Arbitrary Java can be placed in a similar tag. Here the result of running the Java code is not used to replace the tag. Instead you must send output to be inserted by writing to a pre-created PrintWriter called “out”. Here’s the same example using this type of tag:
The JSP page “basic2.jsp” looks like this:
<html>
<head>
<title> Sample JSP Basic Page </title>
</head>
<body>
<% java.util.Date d = new java.util.Date();
int sum = 2 + 2;
%>
<h1> Sample HTML Basic Page </h1>
<p> This is a dynamic web page!
The current time
is <% out.print( d ); %>.
The sum of 2 and 2 is <%= sum %>
</p>
</body>
</html>
Notice the sole difference: a missing “=”. Also note how you can define variables in one scriptlet and use them in a later one. This works because all the scriptlets are collected into a single servlet, in the order they appear. This technique is exploited to easily generate HTML tables from Java arrays:
The JSP page “table.jsp” looks like this:
<html>
<head>
<title> Sample JSP table </title>
</head>
<body>
<h1> Sample JSP table </h1>
<table>
<% for ( int i=1; i<=10; ++i) { %>
<tr><td> <%= i %> </td></tr>
<% } %>
</body>
</html>
when using control-flow statements, always use curly braces.
There are other special JSP tags too. A JSP comment looks like this:
<%-- The client never sees this --%>
(Note you can create a comment with “<% /* comment */ %>” too.) A regular HTML comment tag will be passed to the client with the page but not a JSP comment.
Although the ability to include arbitrary Java code mixed in with your HTML is good, too much code spoils the readability. Remember that JSPs are primarily web pages, and will likely need to be understood by Web designer and not Java programmers. Instead it is better to have complex Java code in a JavaBean, and then just use the proper JSP tag to use the bean. That makes the JSP page much simpler, especially for a non-Java programmer.
To invoke methods of your JavaBeans you use a set of special JSP tags:
<jsp:useBean id="user" class="PersonBean" />
which invokes the default constructor as if you had used:
PersonBean user = new PersonBean();
You can add the attribute “scope” to control the life of the bean object, like this:
<jsp:useBean
id="cart" class="shoppingCartBean"
scope="session" />
to have the cart object created the first time a user visits the page. That same object will be available each subsequent visit by the same user in the same session. The default is page scope, which creates a new instance each time the page is used. You can also specify application scope.
To set and get properties of your bean you use these special tags:
<jsp:setProperty
name="user"
property="name" value="Joe" />
<jsp:getProperty name="user" property="age" />
which invokes the setter and getter methods. The result of using jsp:getProperty is converted to a String and replaces the tag, much like the “<%= expression %>” tag. To make this work, you must compile and install the JavaBeans to the server’s required directory, in tomcat this would be “WEB-INF/classes/”, which is a subdirectory of wherever the JSP is installed (webapps). (I.e., it goes in the WAR.)
You can use a special tag to abandon processing the current page, and cause the JSP server to instead load a different page:
<jsp:forward page="URL" />
This type of tag is often used within if-statements:
<% if (...) {
%>
<jsp:forward ... />
<% } %>
Pre-defined JSP Objects
In addition to out there are a number of pre-created objects you can use:
request is a HttpServletRequest, used to access the data in the request. This can include useful information such as locale, time zone, browser type, user name, client workstation IP address URL information (such as the query string), etc. If the user clicked a “submit” button on some form to get to this page, you can also access the form field values with request.getParameter("name").
response is a HttpServletResponse, used to obtain an output stream out, and to set the response headers (especially the type).
out is a PrintWriter obtained from the response.
session is a HttpSession associated with the request, used to store persistent data for this session only.
application is a ServletContext, which refers to the server itself and allows persistent data to be stored and retrieved by any client from any session.
config ServletConfig, used by the server to initialize servlets.
pageContext is a PageContext, that provides a few useful methods such as getException().
page refers to the Servlet object, and is the same as using this.
Gotchas:
HTML is case-insensitive but XML, JSP, and Java are not. Since all JSP tags are really XML tags, the normal rules apply: All tags must end with “/>” or have a separate closing tag. All values must be quoted with either single or double quotes. If you use double quotes than any Java included inside must escape any double quote with a backslash.
Don’t use a semicolon after expression, but don’t forget them after statements!
Don’t confuse the “id” attribute (used with jsp:useBean) and the “name” attribute (used with jsp:getProperty and jsp:setProperty).
Don’t forget that your bean classes must really meet the JavaBean standard. If not, they will likely compile and run without errors or warnings. But they won’t work!
Servlets
Part of Web Application, see WAR example on website and tomcat install directions (tomcat is reference implementation of the servlet API). Today you rarely need to write a servlet directly. Instead you use JSP. The Java code from the JSP page is collected and compiled automatically as a servlet. (So the first use of a JSP page may be slow.) One good use of a servlet is to control which page to display next. This would be confusing in a JSP. Here’s a small sample:
public class PickPaymentMethod extends HttpServlet
{ protected void doPost ( HttpServletRequest req,
HttpServletResponse res )
{ ...
String nextPage = "/process-" + paymentMethod + ".jsp";
ServletContext sc = getServletContext();
RequestDispatcher rd = sc.getRequestDispatcher( nextPage );
rd.forward( req, res );
}
JSTL — JSP Standard Tag Library (and custom tags)
JSTL encapsulates, as simple XML tags, core functionality common to many JSP applications. For example, instead of suggesting that you iterate over lists using a scriptlet (servlet), or use different iteration syntax from numerous vendors, JSTL defines a standard <forEach> tag that works the same everywhere. Instead of writing JSP this way:
<% if ((User)session.getAttribute("user")).getName() .equals("Joe") { %>
you can use the simpler:
<c:if test="<%= user.name %> == 'Joe'">
This standardization lets you learn a single tag and use it on multiple JSP containers. Also, when tags are standard containers can recognize them and optimize their implementations.
The standard tag library contains 5 collections of tags. These are documented at java.sun.com/products/jsp/jstl/1.1/docs/tlddocs/index.html.
Each collection is called a taglib. The tags all look like:
<taglibName:tagName attr1="val1"
attr2="val2" ...>
body (optional)
</ taglibName:tagName>
If there is no body, just as with standard XML you can use the shortcut “<... />”. If the value is the result of some javabean method call, or (as in the example below) the value of some previously defined Java variable, you use the standard JSP expression syntax to refer to it:
<someTags:aTag attribute="<%= pageContext.getAttribute("aName") %>">
In JSP 2.0 they added a special “expression language”, that allows a simpler way:
<someTags:aTag attribute="${aName}">
Besides fetching data you can use simple math and boolean expressions:
<c:if test="${user.name == 'Joe'}">
[This section incomplete]
In addition to the standard taglibs you can define custom taglibs. This is done by creating java classes with methods for each tag you define in your taglib. Then you create an XML file that tells the web container how to map tag names to classes and methods.
You declare that a JSP page will use tags defined in a tag library by including a taglib directive in the page before any custom tag is used:
<%@ taglib uri="/tlt" prefix="tlt" %>
For more information consult the Sun on-line tutorial at java.sun.com/products/jsp/tutorial/TagLibrariesTOC.html.
Deployment —Anatomy of a Java EE Enterprise Application Archive (EAR)
Java EE code today is mostly Java EE components assembled into an application. It is hoped that some components can be reused as thus reduce the overall cost and time of development. A bundle of similar type of component is called a module. The EJB module will contain all the EJB components, the web module contains all the web server components (JSPs, servlets, and other web files). Additionally some enterprise applications may use thick clients and thus have an application module. Finally some designs use standard interfaces to access EIS components. These interfaces (e.g., database specific JDBC drivers) form a resource access module.
A given application typically has some but not all four modules. For example a very simple Java EE application may only have a few servlets and HTML files, that directly use JDBC to talk to some database. In this case your whole application might only consist of the web module. More commonly you will have both that module and the EJB module.
WARs — Web Archive Files
The web module may consist of one or more Web ARchive files, or WARs. Each WAR is a jar file that contains servlets, JSPs, and other web application components such as HTML files, graphics and other resource files. Sometimes your Java EE application is small and simple, and the entire application can consist of a single WAR. Larger applications may consist of one or more WARs as part of the EAR.
WARs can be deployed in any Web Application server/container (sometimes called a web container, a servlet container, or JSP container), including the popular Tomcat, usually by simply dropping the WAR file into the appropriate place. (Depending on the server you may have to update it configuration, usually by editing an XML file.
Working with EARs
Each module contains the classes (and interfaces) for the components, plus a deployment descriptor that tells the container what components are there, what container services are needed, and how everything hooks together. This description is an XML file. It and the classes are packaged in a jar file, which becomes the module. Note that the EJB and application modules use the regular .jar extension, but the web module jar file should be renamed “.war”, and the resource access module extension should be “.rar”.
The idea is you can list all JARs needed on the CLASSPATH in this file, plus any other options needed. Note for enterprise applications you often need to do other tasks such as initialize a database or define what should be included in the web.xml or deploy.xml files. You may need to specify config data such as JNDI data, persistance.xml (needed to use a DB), logging server config info, etc.
To play with the database, use the JMX console, click on “database=localDB,service=Hypersonic” link, then click on the “Invoke” button below the “void startDatabaseManager() \n MBean Operation” line. This starts up a database management console app.
The (up to four) modules are then packaged in a jar with the extension “.ear”, which forms the Java EE application that can be dropped into the application server (sometimes called an EJB container or Java EE container) for deployment.
EARs also include a deployment descriptor that tells a Java EE compliant application server which services are needed and which classes implement required interfaces. The application server runs code to deploy the EAR components in the right places.
There are few books or resources to help you design a Java EE enterprise application. Most books and on-line resources focus on one or more of the Java EE technologies. There are a couple of case studies though, such as the Pet Store example from Sun, as well as some books from Sun (one of which can be read on-line).
A typical development process for Java EE applications contains two steps:
1. Create JavaServer Pages (JSP), servlets, and other web components that handle the presentation logic of the application; and build Enterprise JavaBeans (EJB) components to manage the application’s business logic.
2. Assemble those components into modules (with the appropriate deployment descriptors), and then combine those modules into an EAR that can be deployed to a Java EE platform-compliant application server, such as Sun’s Application Server PE 8.
The deployable unit can be either of the following:
· Java EE module — A collection of Java EE components that reside in the same container. The modules can be a Web archive (WAR), an EJB Java archive (JAR), a resource archive (RAR), or an application client JAR. Such stand-alone modules are used in tiny applications. (Note RAR is not stand-alone.)
· Java EE application — A collection of Java EE modules, along with application deployment descriptors, in the form of an EAR file.
JBoss Setup
JBoss is a free Java EE application server that supports all Java EE 5 plus EJB 3.0. Visit www.JBoss.com or .org. I think Red Hat has purchased JBoss. This product uses Tomcat for the Web app container part, so you automatically get that too. To develop software and to run your WARs and EARs you use the JARs of your application server. You don’t need the Sun Java EE SDK, but it may pay to bookmark the Javadoc APIs for Java EE.
Download JBoss from labs.jboss.com/portal/jbossas/download
Just click on the “run installer” button. This uses “WebStart” to download and run the installer program. First pick “Eng” for English language installer. Click Next to see some version info and a link to the JBoss.com homepage. Click Next to see the Release notes. It might be a good idea to look those over.
Click Next to see the open source licenses used and to click the “I Agree...” button, then click Next.
Select the installation directory. The default of C:\Program Files\jboss‑4.0.5.GA is fine. Then click Next.
On the next screen you pick which component sets to install. To use the current (new) EJB 3.0, you need to select the “ejb3” choice. You will see a warning that this requires Java SE 5, and that this is not J2SE 1.4 compliant. That’s because the new EJB spec will be part of Java EE 1.5. Note the “all” choice includes cluster-middleware support, but not EJB3.
The next screen is a list of “packs” (really JARs implementing various parts of Java EE. By default, all are checked and that is fine.
On the next screen, you pick the name of the configuration to use. The default is “default”, and if you change that you will have to supply the name on each command line, so don’t change it.
The next screen allows you to select which database product to install and use. If you don’t use the default choice (“Hypersonic SQL”) you will need to install the various drivers and update the config files. I suggest you use the default.
The next screen “Enable deployment isolation/call by value” I don’t understand, so I left the default of unchecked.
The next screen lets you chose to use secure console access (https) and to set the administrator name and password. I left the default (use security) and “admin” username and “admin” password.
The final screen shows your choices. Next the install begins. It didn’t take long!
Now set some environment variables: JAVA_HOME to point to your jdk install directory (this may be set already) and JBOSS_HOME, to where you installed JBoss. On my system: JAVA_HOME=C:\Java\jdk and JBOSS_HOME=C:\Program Files\jboss-4.0.5.GA
Run the Application Server
To start the server run %JBOSS_HOME%\bin\run.bat.
Deploy EARs and WARs with JBoss
To deploy WARs and EARs, copy them into the directory %JBOSS_HOME%\server\default\deploy. (There is a bunch of files in there already.
To run your web app, point your browser to http://localhost:8080/nameOfWarFile. For example: http://localhost:8080/myServletWAR. This should show the index.htm page. To run the servlet use the the URL http://localhost:8080/myServletWAR/hello
(Note! The link in the index.htm file points to .../myServletWAR/servlet/hello, which doesn’t work! The JSP page works though.)
Compiling Java EE Code
To compile your code you need to include the various JAR files with the JavaEE APIs for your Application Server, in this case all the JAR files in %JBOSS_HOME\client\*.jar.
You could copy all these JARs to your JDK JRE’s “ext” (extensions) directory, or list them on the javac cmd-line (with the “-cp” arg), but the common and simplest way is to use an Apache.org tool called “ant”.
Lecture X — Java Web Start
[Adopted from Key Horstmann’s Core Java vol. I, ch. 10, 7th Ed.]
WebStart is an alternate delivery mechanism for “thick” clients. Previously thick clients were applets, with many limitations, or applications that had no security limitations at all and needed to be deployed and updated regularly.
WebStart works by having (almost) regular Java applications that are cached on the local system automatically when first launched from a URL. Thus they launch and deploy like Applets but are in fact applications. Although the JRE comes with a WebStart cache viewer (which allows an easy way to launch and create desktop shortcuts to them) they are typically launched by clicking a URL in a browser. Note the launched application is not a Applet and doesn’t require the browser to run.
WebStart uses a more relaxed security model than applets, but there is still security. A digitally signed application is granted full access. An unsigned application can still access protected resources, with the user’s permission. This works by having your Java WebStart application use different APIs for dangerous operations than normal. If your application uses the normal APIs then the regular applet security model is enforced (?) The API provides access methods for reading/writing files, clipboard access, network access, printing, opening the (default) browser to show an HTML document, and other features.
This API is in the extension jar “javaws.jar” which must be in the classpath. To use the WebStart services the application creates the appropriate service manager object to do the access. Here’s an example of saving a file:
FileSaveService
fss = (FileSaveService)
ServiceManager.lookup( "javax.jnlp.FileSaveService" );
fss.saveFileDialog( ".", new String[]{"txt"},
dataStream, "MyApp" );
See http://java.sun.com/products/JavaWebStart/docs/developersguide.html
To create a WebStart application you compile your application, put it into a clickable JAR file, and create a deployment descriptor to be placed on a web page. When the user clicks the link for the deployment descriptor, the web browser launches javaws.exe, which checks if the latest version of the application is downloaded, and then runs it.
This descriptor is an XML file in Java Network Launch Protocol (JNLP) format. It describes the application, lists the required jars, and optionally asks for full desktop permissions. Note that the web server must report the correct MIME type of this file, or your browser won’t know it is a deployment descriptor and very likely will just display it as text. (The same is true for PDF and other document types.):
notepad
MyApp.java
javac MyApp.java
notepad MyApp.mf (Main-Class: MyApp)
jar -cvfm MyApp.jar MyApp.mf *.class
notepad MyApp.jnlp
<?xml
version="1.0">
<jnlp spec="1.0+"
codebase="http://localhost:8080/myapp/
href="MyApp.jnlp">
<information>
<title>My Demo Application</title>
<vendor>Hymie Piffl</vendor>
<description>This application does nada.</description>
<offline-allowed/>
</information>
<resources>
<j2se version="5.0+"/>
<jar href="MyApp.jar"/>
</resources>
<application-desc/>
</jnlp>
The Web Start environment provides the PersistenceService class that allows your application to safely store data without having full access to your hard drive. The service limits the data size, and only your application can read or write the data. This means that other applications on your hard drive will not be able to access information stored by your application.
Using JNLP to Deploy Applets
This can be done as of Java 6u10. To deploy applets using JNLP, specify the jnlp_href parameter in the applet tag as follows:
<applet
width="300" height="300"
code="com.mycompany.MyApplet">
<param name="jnlp_href" value="my_applet.jnlp">
</applet>
In this example my_applet.jnlp has the following deployment information:
<?xml
version="1.0" encoding="UTF-8"?>
<jnlp href="my_applet.jnlp">
<information>
<title>My Applet</title>
<vendor>My Company, Inc.</vendor>
<offline-allowed />
</information>
<resources>
<j2se version="1.4+"
href="http://java.sun.com/products/autodl/j2se" />
<jar href="my_applet.jar" main="true" />
<extension name="SomeExtension"
href="http://some.server.com/some_extension.jnlp" />
</resources>
<applet-desc
name="My Applet"
main-class="com.mycompany.MyApplet"
width="300" height="200">
</applet-desc>
</jnlp>