While persistent data can be handled in any number of ways, using a
relational database is common.
Java provides JDBC for low-level access to a DBMS,
allowing the use of SQL.
This works (if you are good at SQL and configuring
various DBMSes), but has a drawback with Java:
the results of queries is a table (actually, a ResultSet of
raw SQL data).
To process effectively in Java, this data must be read one field at a time,
for each row, and objects constructed and added to a collection.
This is because Java works best with collections of objects.
More recent versions of Java do include the Java Persistence API, or “JPA”. This includes a much simpler (and more Java-ish) way to access databases and includes its own query language. Long available in Java EE, JPA is now available in Java SE. However, while Java servers generally include an implementation of JPA, neither Java SE JRE nor Java SE JDK implement the classes required. You will need to download (and add to the CLASSPATH) the required Jar file(s) from some persistence provider.
In 2019, Oracle gave JPA to the Eclipse Foundation to manage.
This required renaming the package names from
“javax.persistence” to
“jakarta.persistence”.
Many online tutorials still show the old package names, which can be confusing.
To use JPA with Java SE, you must add and configure an
implementation of JPA.
Initially known as “TopLink”, the reference implementation
is the open source “EclipseLink”.
To use EclipseLink JPA, download the EclipseLink zip archive from
www.eclipse.org/eclipselink/ and unpack it
someplace, say C:\Java\eclipselink.
Next, create an environment variable named ECLIPSELINK_HOME
with the location of the eclipselink folder
(Not strictly needed for this demo).
Finally, you must make sure both eclipselink.jar and
jakarta.persistence-api.jar
are found in the CLASSPATH.
(Look in ECLIPSELINK_HOME\jlib and
ECLIPSELINK_HOME\jlib\jpa for these two Jars.)
EclipseLink internally used log4j for logging (even though
the documentation says it doesn't), thru version 2.6.
In the persistence.xml JPA configuration file,
logging is disabled for this demo.
However, log4j still launches, finds it isn't configured
correctly, and displays annoying error messages.
To prevent this, the file log4j.properties is used with
the simple directive to disable logging.
(This does not seem to be a problem in a version 2.7, and you can safely
delete the log4j.properties file.)
This demo uses the Apache Derby database. See Derby Demo for installation instructions. For simplicity, the demo uses an embedded database so you don't have to set up any server. The downside of using embedded databases is that it becomes difficult to bundle your application in a Jar file. This is because any read-write database must be outside of that jar file, which requires extra careful configuration, and permission to create files and folders on the user's hard disk.
To run this demo, extract the folder JPAdemo from
JPAdemo.zip.
(Or, save the individual files shown below,
preserving the folder structure as shown.)
Then you can compile and run it, like so:
C:\Temp>cd JPAdemo C:\Temp\JPADemo>javac com\wpollock\jpademo\Main.java C:\Temp\JPADemo>java com.wpollock.jpademo.Main Titles of books in our collection: ID: 1, Title: Underwater Basket-Weaving for Dummies ID: 2, Title: Brain Surgery: Self-Taught Number of books: 2 C:\Temp\JPADemo>
This demo is easier using some IDE or a build tool such as
Maven.
But all the demos I can find online do that, so I wanted to show the
basic way using nothing but the JDK and EclipseLink.
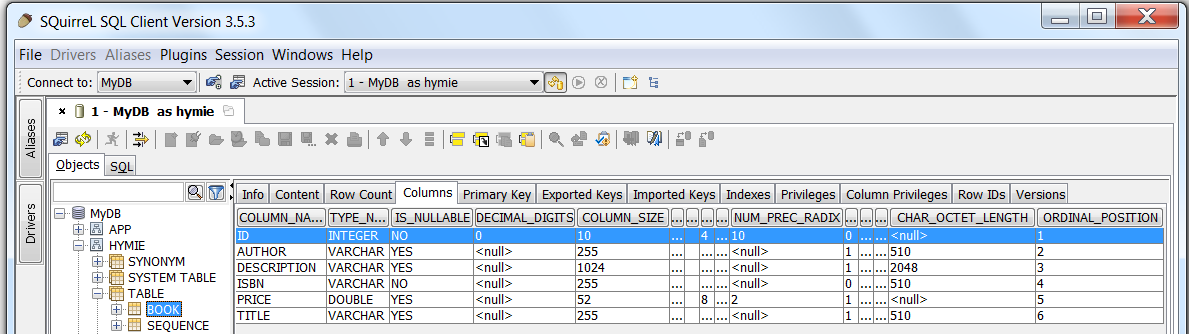
(You can explore the Derby embedded database created in the
MyDB directory.)
The two graphics links below show the resulting database table (screen-shots from SquirrelSQL).
JPADemo META-INF com 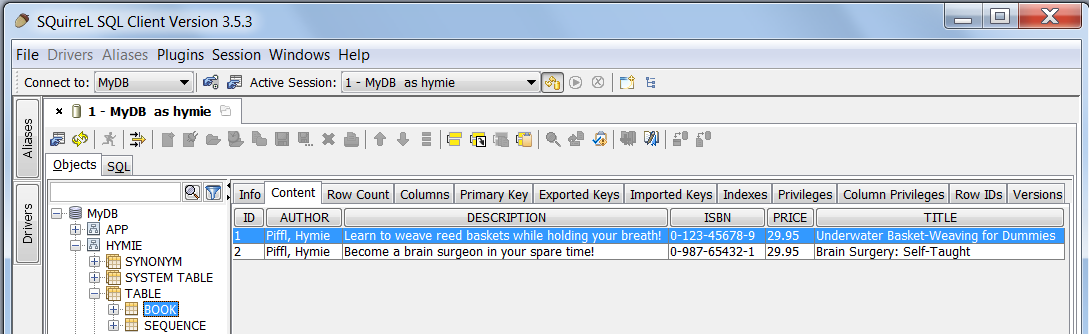{kind=link}
{kind=link}