Given such a table, you can ask queries such as "what is the name of person 0002?" and "what is the phone number of Jane Doe?".
Schemas
The design for a database affects its usability and performance in many ways, so it is important to make the initial investment in time and research to design a database that meets the needs of its users. A database schema is the design or plan of the database, and includes:
- what data is to be stored
- the type of each piece of data (e.g., text, number, phone number, date, ...)
- how the data will be organized (i.e., what tables to have)
- any constraints or limits on the data (e.g., number ranges, length of text string)
- how the various data relate to one another.
The term schema has another meaning: a group of database objects (that is, tables, views, indexes, stored procedures, triggers, sequences, etc.). In this sense, a schema is a namespace, used to conveniently assign permissions to a number of objects (tables), and to allow reuse of (table) definitions in several different databases. Usually there is a default schema for a given database.
A user can access objects in any of the schemas in any database they can connect to, provided they have the proper privileges.
A database management system (DBMS) handles all the actual file reading, writing, locking, flushing, and in general handles all the details of the CRUD operations so the data is efficiently and safely managed. It also handles other common operations such as managing network parameters, database creation, schema definition, security, etc.), that are needed to work with databases.
Once set up, a DBMS system can be used by an application to read data, parse it, and store it, so it can be efficiently searched and retrieved later. An application connects to the DBMS, indicates which database to use, and supplies a username and password.
A given DBMS many run several independent instances on a given server. Each instance may manage one or more databases (catalogs), which contain the tables from one or more schemas.
Once connected, an application sends various query and update (CRUD) statements to the DBMS. Note that these query and update statements, often written using a standard language such as SQL, only say what you want. Thus SQL differs from most programming languages in which you must express how to do something.
The database can be structured in various ways: plain old files, in tables of rows and columns, or as named objects organized in a hierarchy. So why use a DBMS?
Enterprise applications all have similar data storage needs: they often require concurrent access to distributed data shared amongst multiple components, and to perform operations on data. These applications must preserve the integrity of data (as defined by the business rules of the application) under the following circumstances:
- distributed access to a single resource of data, and
- access to distributed resources from a single application component.
Plain files don't support this use. In the old days (1950s–1970s) developers decided what questions were going to be asked (for decision support DBs) or what data to capture (for OLTP DBs), designed a schema for the data (what tables and columns were needed), and implemented the whole thing in COBOL (shudder). But soon it was realized that these enterprise applications all had similar needs and differed only in the specific schema and connection details. It was a waste of time to re-implement the same functionality afresh in each application. Putting the common parts in a DBMS greatly speeds database application development and helps ensures the functionality is well-implemented and error free.
Note that while a single DBMS can serve multiple databases simultaneously, in practice the network bandwidth requirements, large disk space requirements, and different security and backup policies make this impractical. Having one host running one DBMS which serves a single database is a common practice.
A Relational Database Management System (RDBMS) is a system that allows one to define multiple databases simply by providing the schemas, and can preserve the data integrity. Today's RDBMSes do this very well; some can support a large number of tables, each with a huge number of rows of data (terabytes and more), for hundreds of simultaneous clients. Most support additional features and management tools as well.
All RDBMSes today support a common language to define schemas and queries in: SQL (Structured Query Language). The language has three parts, the Data Definition Language (DDL, the SQL where you define and change schemas) and the Data Manipulation Language (DML, the SQL where you lookup, add, change, or remove data). The third part is used to manage the server and the databases; this may be called Data Control Language or DCL. However this is the most recently standardized part of SQL and the least well supported; most DBMSs use non-standard commands for this. SQL supports software's need for CRUD. Each letter in the acronym CRUD can be mapped to a standard SQL statement: INSERT, SELECT UPDATE, and DELETE.
System administrators need to be most familiar with DDL and DCL, since it will usually be their job to manage the DBMS and create and manage the databases. Software developers need to be most familiar with DML. A DBA should be expert with all parts. But everyone should know something about each part of SQL.
Although SQL is an ISO and ANSI standard, most RDBMSes only partially support the standard or add proprietary extensions that are very useful. This makes changing your RDBMS vendor difficult, as migrating your data, schemas, and queries can be painful. It doesn't help that the standard changes dramatically every 4 years or so, and that some parts of the standard are marked as optional. Here is a brief list of the SQL standard versions:
- 1986 — First adopted by ANSI and commonly
called
SQL-86
orSQL-87
. - 1992 — Major revision adding many missing features, and
adopted as ISO 9075, commonly called
SQL2
,SQL92
or sometimesANSI-SQL
(all versions are standardized by ANSI). - 1999 — Major revision adding new data types, regular
expressions, some procedural statements, triggers, and more; commonly
called
SQL3
,SQL99
, orSQL:1999
. - 2003 — Added some XML support, sequences, and
automatically generated column values (e.g., the next ID
number); commonly called
SQL:2003
. - 2006 — Added significant XML support.
- 2008 — Minor revision but with some new features added, this is the latest version (as of 3/2011).
In addition to supporting different sub-sets of SQL (all modern ones support at least SQL-92), different RDBMSes support different configuration methods and security models and need expertise for tuning the system (adjusting RDBMS parameters and re-working some queries and schemas) to provide good performance.
A modern DBMS reads in the query and generates several possible execution plans. Each plan is essentially a program; a series of low-level disk access operations. All of the plans are correct; when run each results in the same answer to the query. They differ only in their efficiency. Picking the wrong plan can make a large difference in the time it takes when answering the query. The various execution plans are compared using cost-based query optimizers, and the most efficient (lowest cost) one is chosen and used.
A badly tuned system can take hours/days rather than seconds/minutes for
some operations!
It is up to a database administrator (DBA
) to tune
the DBMS by setting various parameters, so it stores
the data efficiently and generates efficient execution plans.
Comparing Popular RDBMSes
By far the most capable and popular commercial RDBMS is Oracle (about 40% market share), with IBM's DB2 also popular (~33%). Microsoft SQL server has about 11% (as reported by IDC at databases.about.com '10). However in recent years a number of open source alternatives have established themselves: MySQL and PostgreSQL (or Postgres) are two common ones (with a reported market share second only to Oracle). There are free versions of all popular RDBMSes available, usually with limited licenses (e.g., restrict number of connections to one).
Of the open source DBMSes,
MySQL is more popular than PostgreSQL.
It is very fast for certain applications
and works very well with PHP, so has become a de facto standard
for web development (LAMP: Linux, Apache, MySQL,
and PHP).
The heart of any DBMS is the DB engine.
MySQL supports several, each tuned for a different purpose.
The MyISAM engine is the fast one, but it isn't suitable for
OLTP.
The InnoDB supports features similar to PostgreSQL and other
RDBMSes but is not very fast, and has been bought by Oracle
(while the rest of MySQL was bought by Sun).
FYI: The DB engine for Microsoft Access
DBMS is called the Jet
engine.)
In 2010 Oracle bought Sun Microsystems and now owns all their assets,
including MySQL.
In 2011, Oracle added some proprietary enhancements to MySQL,
moving it toward a non-free, non-open source model;
its future is uncertain.
MariaDB
is a community-developed fork
of MySQL,
released under the
GPL.
Its lead developer is Monty Widenius, the founder of MySQL,
who named both products after his daughters My and Maria.
Another fork of MySQL worth knowing is
Percona,
developed by the former performance engineer of MySQL.
PostgreSQL supports more of the current SQL standard and has advanced features (e.g., multiple schemas per DB), and can be very fast for some uses. It's a fine all-around RDBMS. It is also becoming popular as developers shy away from the uncertain future of MySQL. It is recommended for new deployments when you don't have a legacy MySQL system to worry about.
Small DB libraries to embed in your application such as
SQLite are popular
too.
These only support one client application with one DB,
but that is fairly common.
(For example Firefox web browser uses SQLite to store bookmarks
and other data.)
For more insight on the differences between popular RDBMSes
see wikipedia.org,
Comparison_of_relational_database_management_systems
.
JavaDB (a.k.a. Apache Derby) is good for small to medium sized databases (up to a few tens of millions of rows each for dozens of tables), and is bundled with Java. MySQL/MyISAM (now owned by Oracle) is a great choice for gigabyte sized databases that require fast connects, such as for web applications, but doesn't support transactions. For OLTP, use PostgreSQL, MySQL/InnoDB, or the new (2012) VoltDB. Go with a commercial DBMS such as Oracle or DB2 for Terabyte sized DBs. (Google's database is measured in Petabytes, and they use a custom built DBMS called BigTable.)
Note even a small DB needs to be well designed (including proper indexes) or it will suffer performance issues.
Defining Relational Databases
When defining a relational database you need to specify the database name,
how (and by whom) it can be accessed, and the schema that defines the various
tables in the database.
(Other items may be defined as well, such as procedural functions, triggers,
sequences, views, etc.)
The heart of the database is the schema; for each table you need to
specify the name of the table, the attributes' names and their datatypes, and
any constraints on the columns or the table as a whole.
Tables can be defined with the SQL
CREATE TABLE statement.
After the table is created, the schema can be changed
with the ALTER TABLE statement, but this can be dangerous
and slow if the table already contains lots of data.
Datatypes are the names given to the types of each attribute (column), but are not well standardized. Common ones include Boolean, integer, float, fixed-length and variable-length strings, binary objects, as well as currency and dates, times, and intervals. Every attribute must be assigned a datatype.
Constraints are used to limit the type of data that can go into a table. Some of the commonly available constraints (depends on the DBMS used) are:
- NOT NULL A null value is a special
value that means
no data
. Use this constraint to prevent creation of a row of data with a null for some column. - UNIQUE Unique means no duplicates allowed in that column.
- PRIMARY KEY A primary key is a column (or set of columns) that are not null and unique. A table can only have one primary key defined. Usually an index is created automatically for the primary key.
- FOREIGN KEY A foreign key constrains the values in a column to be primary keys from some other (specified) table. This is useful to prevent updates from causing inconsistent data. This is sometimes called referential integrity. The techniques known as cascading update and cascading delete ensure that changes made to the linked table are reflected in this table.
- CHECK This constraint is used to limit the value range
that can be placed in a column.
A CHECK constraint on a single column allows only certain values for that column;
on a table, it can limit the values in certain columns based on values in
other columns in the same row.
The constraint is some Boolean expression, such as
.age > 0 - DEFAULT Not really a constraint, it specifies a default value to be inserted for new rows that don't specify a value for that column. (Has no effect on pre-existing rows.)
Joins and Referential Integrity
Foreign key constraints depend on data from multiple tables.
The data in multiple tables are linked using an operation called a
join
.
A join essentially builds a composite
table from two (or more) tables that have a common column.
For example suppose you have a book table with a
book_number, title,
and publisher_code, and a publisher table with
publisher_code and publisher_name.
Then you can do a
SELECT (or other action) on the composite of these to
show the title and publisher_name.
You can also ensure only valid publisher_code values are
added to the book table.
There are four types of joins, but it is probably enough for a system administrator to just know the names of them: an inner join (the column has the same value in both tables), a left (outer) join (all the rows from the left table even if no matching value in the right table), a right (outer) join, and a full (outer) join (all rows from both tables become rows in the composite table). With outer joins, missing values show as nulls. Also note that nulls don't match anything, not even other nulls, and should be prevented by the schema when possible.
Normalization
Normal forms are a way to prevent DML operations from either destroying real data or creating false data. That can happen if the schema isn't designed for the types of queries and multi-user activity that is common. Creating normal forms is a straight-forward process of transforming a schema from normal form n to normal form n+1. Although there are many normal forms (at least 9, or over 300, depending on how you count them), normal forms 4 and higher cover obscure potential problems that very rarely ever manifest, or can be dealt with in other ways. Practically, most DB schema designers are happy with third normal form.
[The following example was adapted from Joe Celko's SQL for Smarties, 2nd Ed. ©2000 by Morgan Kaufmann Pub., chapter 2.]
Consider a schema for student course schedules. The original design might be something like this:
Classes (name, secnum, room & time, max seats available, professor's name,
list of students (1..max seats available) )
where each student has (name, major, grade).
First Normal Form
requires no repeating groups; each column value must be a single value
and not a list as stated above.
This Classes schema violates this by having an attribute
list of students
.
This schema can be converted (normalized) to
1st NF as a single legal
SQL table, where each row can be uniquely identified by the
combination of (course, secnum, studentname).
The SQL for the revised schema would be something like this:
CREATE TABLE Classes (course CHAR(7) NOT NULL, secnum INTEGER NOT NULL, time INTEGER NOT NULL, room CHAR(7) NOT NULL, maxSeatsAvail INTEGER NOT NULL, profname CHAR(25) NOT NULL, studentname CHAR(25) NOT NULL, major CHAR(15) NOT NULL, grade CHAR(1) );
This schema is in first normal form, but still leads to various anomalies:
-
If Prof. Pollock wins lotto and quits,
you could delete all his classes by deleting all rows with
profname="Pollock". But this also deletes the information about what students are taking Unix/Linux classes (deletion anomaly). - If a student changes a computer course to, say an English poetry course, the database will suddenly show Prof. Pollock as teaching poetry (update anomaly). With this schema it would be up to the application code to also update the other attributes in the row where a student changed their course.
- If HCC hires a new instructor, there is no way to store that until that instructor has been assigned at least one class with at least one student in it (insertion anomaly).
Complex application update logic, query checking, and allowing NULLs would solve some of these problems but not all. Such ad-hoc solutions are impossible to maintain over the long run as your database grows. Many of these problems fade away if each table represents a single fact only. That means the queries may work on several tables at once, but a RDBMS is designed for exactly that.
Second Normal Form
breaks up tables from a schema in 1st NF
that represent more than one fact
into multiple tables, each representing a single fact.
This can be understood with the idea of a table key.
Each table should have a column or group of columns that uniquely identifies
a given row.
In the schema above the key is (course, secnum, studentname).
In 2nd NF, no subset of a table key should be useable to uniquely identify
any non-key columns in a table.
If they can then the table represents multiple facts.
Our table violates 2nd NF
since (studentname, course) alone
determine the (secnum) (and thus all other columns).
Checking for other column dependencies shows
(studentname) determines (major).
To transform this 1st NF schema into a
2nd NF one we need to make sure that
every column of each table depends on the entire key for that table.
Apparently our database represents three facts
:
data about courses, data about
sections, and data about students.
One possible way to convert the schema into 2nd NF
is to split the one table into three tables like this (note the additional
constraints used, just to show how to use them):
CREATE TABLE Classes
(course CHAR(7) NOT NULL,
secnum INTEGER NOT NULL,
time INTEGER NOT NULL,
room CHAR(7) NOT NULL,
maxSeatsAvail INTEGER NOT NULL,
profname CHAR(25) NOT NULL,
PRIMARY KEY (course, secnum),
FOREIGN KEY(secnum) REFERENCES Sections(secnum)
);
CREATE TABLE Sections
(secnum INTEGER NOT NULL,
studentname CHAR(25) NOT NULL,
grade CHAR(1),
PRIMARY KEY (secnum, studentname),
FOREIGN KEY(studentname) REFERENCES Students(studentname),
CHECK (grade IN ("A", "B", "C", "D", "F", "I"))
);
CREATE TABLE Students
(studentname CHAR(25) NOT NULL,
major CHAR(15) NOT NULL,
PRIMARY KEY (studentname)
);
However this schema is also not in second normal form! The Sections table represents information about both sections and about student grades. After splitting that table into two, the final 2nd NF schema becomes:
CREATE TABLE Classes
(course CHAR(7) NOT NULL,
secnum INTEGER NOT NULL,
profname CHAR(25) NOT NULL,
PRIMARY KEY (course, secnum),
FOREIGN KEY(secnum) REFERENCES Sections(secnum)
);
CREATE TABLE Sections
(secnum INTEGER NOT NULL,
time INTEGER NOT NULL,
room CHAR(7) NOT NULL,
maxSeatsAvail INTEGER NOT NULL,
PRIMARY KEY (secnum)
);
CREATE TABLE Students
(studentname CHAR(25) NOT NULL,
major CHAR(15) NOT NULL,
PRIMARY KEY (studentname)
);
CREATE TABLE StudentGrades
(secnum INTEGER NOT NULL,
studentname CHAR(25) NOT NULL,
grade CHAR(1),
PRIMARY KEY (secnum, studentname),
FOREIGN KEY(studentname) REFERENCES Students(studentname),
FOREIGN KEY(secnum) REFERENCES Sections(secnum),
CHECK (grade IN ("A", "B", "C", "D", "F", "I"))
);
This four table schema can answer the same queries as the original single table one, but those queries and updates will be more complex. For example to answer the question what courses is a given student taking? or what is the grade for a given student in a given course?, you will need to use queries with joins.
If you're wondering why the primary key for table Classes
is not just secnum, it's because at my school the
section numbers can be reused.
The real key is probably (secnum, year, term), but
I didn't wish to clutter up the example with all the attributes
that would be required in the real-world
.
Although many anomalies are now addressed, notice that
maxSeatsAvail not only depends on the key for
Sections, but also on the room column.
This is sometimes called a transitive dependency:
room depends on section
and maxSeatsAvail depends on room.
Such a dependency is only acceptable in certain cases and requires
careful application logic so the data doesn't get corrupted.
(That is, the application must remember to update
maxSeatsAvail whenever the room is changed.)
This leads to...
Third Normal Form transforms a schema in 2nd NF by splitting up tables even more than was needed for 2nd NF. To split up the table to remove the transitive dependency, note that 2nd (and 3rd) NF might have multiple possible keys for a table. One is the primary key and the others are called candidate keys. This notion of candidate keys can be used to define 3rd NF:
In 3rd NF, suppose X
and Y are two columns of
a table.
If X implies (determines) Y,
then either X must be the (whole) primary key, or
Y must be (part of) a candidate key.
maxSeatsAvail has this problem:
room is not the primary key nor part of any candidate
key, but maxSeatsAvail depends (only) on
room.
To transform this schema into 3rd NF
we split the Sections
table into Sections and Rooms tables:
CREATE TABLE Classes
(course CHAR(7) NOT NULL,
secnum INTEGER NOT NULL,
profname CHAR(25) NOT NULL,
PRIMARY KEY (course, secnum),
FOREIGN KEY(secnum) REFERENCES Sections(secnum)
);
CREATE TABLE Students
(studentname CHAR(25) NOT NULL,
major CHAR(15) NOT NULL,
PRIMARY KEY (studentname)
);
CREATE TABLE Sections
(secnum INTEGER NOT NULL,
time INTEGER NOT NULL,
room CHAR(7) NOT NULL,
PRIMARY KEY (secnum)
);
CREATE TABLE Rooms
(room CHAR(7) NOT NULL,
maxSeatsAvail INTEGER NOT NULL,
PRIMARY KEY (room)
);
CREATE TABLE StudentGrades
(secnum INTEGER NOT NULL,
studentname CHAR(25) NOT NULL,
grade CHAR(1),
PRIMARY KEY (secnum, studentname),
FOREIGN KEY(studentname) REFERENCES Students(studentname),
FOREIGN KEY(secnum) REFERENCES Sections(secnum),
CHECK (grade IN ("A", "B", "C", "D", "F", "I"))
);
Any good database book (see reviews at www.ocelot.ca/design.htm) will show you how to address other problems with additional normal forms. For example this schema still allows multiple sections to be assigned the same room at the same time, or one professor teaching multiple courses at the same time. A good schema would make (most) such anomalies impossible. The alternative is to design queries, inserts, updates, and deletions very carefully, with extra care taken to locking tables (to prevent data corruption from simultaneous queries and updates). Obviously it is better if the schema design prevents such corruption from ever occurring.
It isn't a system administrator's job to create schemas for most of the organization's databases. But SAs are expected to be able to create simple schemas for IT uses, and to understand normal forms in general in order to work with DBAs and developers.
Transactions
It is often required that a group of operations on (distributed) resources be treated as one unit of work. In a unit of work, all the participating operations should either succeed or fail (and recover) together. In case of a failure, all the resources should bring back the state of the data to the previous state (i.e., the state prior to the commencement of the unit of work). (Ex: transfer money between accounts.)
The concept of a transaction, and a transaction manager (or a transaction processing service) simplifies construction of such enterprise level distributed applications while maintaining integrity of data. A transaction is a unit of work that has the following properties:
- Atomicity: A transaction should be done or undone completely and unambiguously. In the event of a failure of any operation, effects of all operations that make up the transaction should be undone, and data should be rolled back to its previous state.
- Consistency: A transaction should preserve all the invariant properties (such as integrity constraints) defined on the data. On completion of a successful transaction, the data should be in a consistent state. In other words, a transaction should transform the system from one consistent state to another consistent state. For example, in the case of relational databases, a consistent transaction should preserve all the integrity constraints defined on the data.
- Isolation:
Each transaction should appear to execute independently of other transactions
that may be executing concurrently in the same environment.
The effect of executing a set of transactions serially should be the same
as that of running them concurrently.
This requires two things:
- During the course of a transaction, intermediate (possibly inconsistent) state of the data should not be exposed to all other transactions.
- Two concurrent transactions should not be able to operate on the same data. Database management systems usually implement this feature using locking.
- Durability: The effects of a completed transaction should always be persistent.
These properties, known as ACID properties, guarantee that a transaction is never incomplete, the data is never inconsistent, concurrent transactions are independent, and the effects of a transaction are persistent.
SQL Basics
Most SQL statements are called queries or
updates,
and can be entered on one line or several lines.
They end with a semicolon (
), although not all
DBMSes will require this.
The SQL keywords are not case sensitive; only data
inside of quotes is case sensitive.
SQL uses single quotes around literal text values
(some systems also accept double quotes).
(Some SQL DDL statements were shown above
when defining a schema for normal forms.)
;
Some of the more common Data Manipulation Language (DML) SQL statements (the ones used for CRUD) include: INSERT, SELECT (to find and show data), UPDATE, and DELETE. Some examples of these are:
INSERT INTO table (col1, col2, ...) VALUES (val1, val2, ...);
SELECT [DISTINCT] col1, col2, ...
(or use wildcard *
instead of a column list)
FROM table [, table2, ...]
WHERE condition (e.g. WHERE amount < 100)
ORDER BY col;
UPDATE table SET col2 = value2, col3 = value3, ...; WHERE condition; (e.g. WHERE col1 = value1)
DELETE FROM table WHERE condition; (e.g. WHERE col1 = value1)
A great way to practice and learn SQL is to use the SQuirreL SQL GUI client. This is a portable Java application (so you need to install Java first!) that is easy to use with any database. See SquirrelSQL.org to download or for more information.
Other SQL commands aren't as well standardized. They are used for defining schemas (Data Definition Language, or DDL) and for DBMS control operations (Data Control Language, or DCL). Some of the more common ones include: CREATE, ALTER, DROP, GRANT and REVOKE.
There is no standard SQL to list the databases (the SQL standard uses the term schema) available on some server.
However there is a standard SQL query to list the schemas in a database (the SQL standard uses the term catalog). (Note Some DBMSes don't support schemas, or don't follow the standard, e.g., DB2 and Oracle). For compliant RDBMSes use:
SELECT SCHEMA_NAME FROM INFORMATION_SCHEMA.SCHEMATA
Not all RDBMSes support the following standard SQL to list the tables in a DB/schema:
SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'name'
(Oracle uses
;
DB2 uses SELECT * FROM TAB
instead of
SYSCAT
.)
INFORMATION_SCHEMA
Using INFORMATION_SCHEMA it is possible to describe
(list the columns and their types and constraints) any table,
but not all RDBMSes support this.
For Oracle use
and for DB2 use
DESCRIBE tablename
.
DESCRIBE TABLE tablename
A system administrator also needs to know a little about: indexes (makes searching tables faster), views (virtual tables), sequences (generates the next number each time it is used), tablespaces (allows grouping of tables on the disk), triggers (do a task automatically when some condition occurs), functions, and stored procedures. While not all RDBMS systems support all these features, you do need to understand what they are. Here is an example using a sequence:
CREATE SEQUENCE seq;
INSERT INTO foo (id, name)
VALUES (nextval('seq'), 'Hymie');
See one of the on-line SQL tutorials for more information; one of the best is sqlzoo.net, and the SQL tutorial at w3schools.com is pretty good too. I like the book The Manga Guide to Databases as an introduction, but I use on-line sources to learn SQL, especially when learning the non-standard SQL for some particular DBMS.
MySQL
The documentation for MySQL includes tutorial introductions and reference information, but a system administrator can get by with much less information, shown here. (Learning to install and configure a DBMS is covered elsewhere.)
MySQL includes a powerful security system.
Users can be identified as local users or remote users (from a
specific host, or from anywhere).
A user can be given privileges on a database, or just specific tables,
and the permissions can be very selective from just look
to
full access.
A user can be granted administrator (super-user) privileges as well.
In the examples below, substitute your values for the underlined italic
words:
To create a database:
mysql> CREATE DATABASE dbname
Running MySQL from the command line:
$ mysql -u user [-h host] -p
Changing passwords:
# mysqladmin -u user password secret
The root user (or any user with appropriate privileges) can also change passwords from inside the MySQL database:
mysql> SELECT * FROM mysql.user WHERE user = "user"\G
mysql> SET PASSWORD FOR "user@localhost"=password('secret');
mysql> SET PASSWORD FOR "user@%"=password('secret');
(Ending a query with
instead of a semicolon results in
a vertical output format, useful when there are many columns.)
\G
Adding users:
(If using mysqladmin, remember to run
after making
the change.)
mysqladmin reload
mysql> GRANT ALL PRIVILEGES ON *.* TO "user@localhost" IDENTIFIED BY 'secret' WITH GRANT OPTION; mysql> GRANT ALL PRIVILEGES ON *.* to "user@%" IDENTIFIED BY 'secret' WITH GRANT OPTION;
Deleting users:
mysql> DELETE FROM mysql.user WHERE user = 'user';
MySQL configuration and security model: define some users.
Define a DB (
),
add some tables, add some data, and do some queries.
[Project idea: implement a MySQL DB for an on-line
greeting e-card site.
(See HCCDump.txt.)]
create database name;
To recover a lost password, log in as root and change it
as shown above.
To recover a lost root password, stop the server.
Create a text file ~root/reset-mysql-pw
with these two SQL statements:
UPDATE mysql.user
SET Password=PASSWORD('secret') WHERE User='root';
FLUSH PRIVILEGES;
Then restart the server with:
mysqld_safe --init-file=~root/reset-mysql-pw &
When this has worked, delete the file (it contains a password), and restart the server normally.
PostgreSQL
PostgreSQL
(which is pronounced
post-gres-q-l) is often just called Postgres
, the original
name before it switched to use SQL.
Originally it just used Unix system user accounts, so
no extra effort was needed to add users.
For modern versions (currently version 9) you must instead add a
role for each user who is allowed to connect to the server.
The rules for authenticating users are controlled by a
configuration file,
/var/lib/pgsql/data/pg_hba.conf.
The default for local (non-network) user access via the
psql command line tool is to just trust them.
So you should not need to use a password!
(This can be changed to increase security.)
Other choices include pam, ldap,
md5, ident sameuser
(often used for local access, this means allow a user to connect
without a password using their system login name as the role name),
and others.
In PostgreSQL a user is really just a role. Creating users with CREATE USER is the same as CREATE ROLE WITH LOGIN (i.e., a role with login privilege).
PostgreSQL security system is a bit simpler to understand
than the MySQL system.
With PostgreSQL the owner of some object
(e.g., a database or a table) can do anything to it, as can any
PostgreSQL administrator user (or PostgreSQL superuser).
All other users must be granted access to objects using the
SQL GRANT and REVOKE commands.
When adding user roles to PostgreSQL use either
the CREATE ROLE non-standard SQL command,
or the command-line tool createuser.
With this tool you can also put in a password for the
user.
There is also a dropuser utility that
matches the similar (non-standard) SQL command.
Roles are stored in pg_catalog.pg_roles.
This table can be modified to change properties or passwords
of users:
To work with PostgreSQL you must configure
pg_hba.conf (or live with the defaults),
initialize the database system (done as part of the install;
you only need do this step once), and then start it running.
How that is done depends on your system.
For some older systems, you can run:
# export PGDATA=/var/lib/pgsql/data # cd /tmp # su -c 'initdb' postgres # start the server using system-specific method
On Sys V init based systems, such as Fedora 15 or older, you can use:
# /etc/init.d/postgres initdb # /etc/init.d/postgres start
For Fedora 16 and newer Red Hat systems, systemd has replaced Sys V init scripts, and you can't do this anymore. Instead, run this:
# postgresql-setup initdb # service postgresql start # or: systemctl start postgresql.service
The only admin (actually the only user) initially is
“postgres”.
After starting the server, create the user root
within postgreSQL:
# cd /tmp # su -c 'createuser -s root' postgres
The only admin (actually the only user) initially is
.
So the above command makes postgresroot an administrator too
(the
option).
(Note that user -spostgres may not have access to
your home directory, so to avoid an error message you should
cd into a public directory such as /tmp
before running this.)
To allow the use of the PostgreSQL procedural language
extensions to SQL, you must add this language
to a database first.
You can do this now to the default template used when creating
new databases.
You can do this as root (since root
is now a PostgreSQL administrator) but this isn't a good idea.
So add the language as user postgres:
# cd /tmp # su -c 'createlang plpgsql template1' postgres
(This may be done automatically on newer systems; if so, you will see a harmless error message.)
Finally we are ready to create a database
for some user.
First you must add the username as a new role
in PostgreSQL.
Then you can create a database owned by that user,
using SQL or the command line utility
createdb.
Note that createdb defaults to creating
a database named for the current user (and owned by that user).
Since root has database creation privileges,
note how simple the example below is:
# createdb # Create a DB named root, owned by root # createuser auser # createdb -O auser auserdb
(You can add a comment for your DBs with additional arguments.)
Running PostgreSQL from the command line:
$ psql [-d database [-U user]
Or:
# psql -d auserdb -U auser
(Note if you log in as auser, then you can
omit the command line arguments.)
The last step is to enable your database server to start automatically at boot time. Again, your init system dermines how this is done. On Fedora 16 or newer with systemd, do this:
# systemctl enable postgresql.service # or: chkconfig postgresql on
Changing passwords with PostgreSQL:
\x SELECT * FROM pg_catalog.pg_roles WHERE rolname = 'auser'; ALTER ROLE auser WITH PASSWORD 'secret'; \x
The
toggles vertical or horizontal output
of rows.
For displaying a single row with many columns, I prefer
the vertical (or expanded) output format.
Besides the password you can alter the other role properties
too.
\x
Adding users to PostgreSQL:
username=# CREATE USER name WITH PASSWORD password;
Deleting users:
username=# DROP ROLE user;
Solaris 10 PostgreSQL Setup
In Solaris 10 with PostgreSQL 8.2 pre-installed, you need to do this:
- Set PATH: PATH=/usr/postgres/8.2/bin:${PATH}
- Set MANPATH: put /usr/postgres/8.2/man before any other pathnames.
- The environment variable
PGDATAneeds to be set to the fully qualified pathname to where the PostgreSQL data directory is located. The default location for PostgreSQL data is/var/postgres/8.2/data. If you setPGDATAthen you will not have to use the
option for those PostgreSQL commands that need to know the pathname to the data directory. In a production environment the database files should be in their own filesystem partitions. Make sure there is sufficient space for growth. Pick a filesystem type for performance and availability.-D - Use
scvadm -v enable -s postgresql:version_82 - You can now test the database, by connecting to the database named
postgres
, running on the default port:psql postgres - To configure the database, modify the file
postgresql.confin the database directory. For Solaris tips on tuning PostgreSQL, visit: www.sun.com/servers/coolthreads/tnb/applications_postgresql.jsp
Scaling and Reliability
DBs are often a vital part of an enterprise, and must be highly available. This often means using some duplicate hardware in order to improve reliability (includes servers and disks). Also clusters are sometimes used to provide transparent failover and load balancing.
DBMS Tuning — A Dark Art
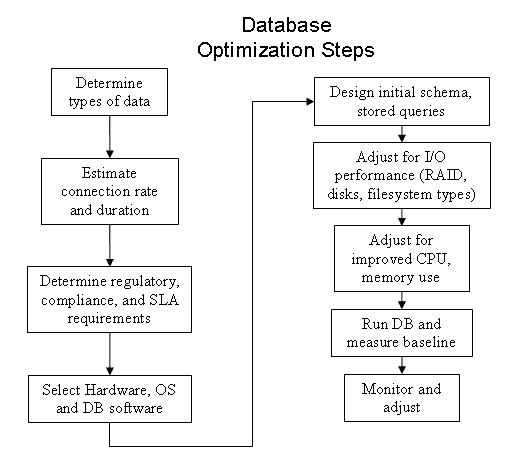
The first task is to make sure the database is running on appropriate hardware. Modern SCSI (such as SAS) may be best, but SATA will work well too. Make sure it is modern or it may not support write barriers correctly. Use enterprise grade disks. Aside from spinning 2 or 3 times as fast as consumer grade ones, the firmware is better and more predictable (replacing a consumer grade disk, even with the same model, may not result in the same disk firmware.) Enterprise disks can also have non-volatile write caches (backed up with a battery or large capacitor).
Next, decide on central storage (SAN or NAS), or DAS. DAS may perform better (no network latency and no HBA, network switch, or OS write caches between your OS and the drives) but are not as flexible and may cost the same or more than central storage. When using a NAS or SAN, network congestion is another factor. (I'm not sure what you can do about it, except upgrade your storage infrastructure.)
Turn off any OS LVM or software RAID. As for RAID, most database servers will work best with RAID-10. This give similar reliability to RAID-5 or RAID-6, but without parity calculations to slow down disk writes.
Finally, you will do best if you use the lower numbered cylinders (outer edge) of any disks for the logs and database tables, and use the slower inner cylinders for OS and other system files.
Once the hardware is selected it is time to consider tuning the filesystems and OS. First off, make sure you use a modern kernel version. Many have improved disk software a lot in recent years (2011).
Two key points for the SA are to use a safe filesystem type
(e.g., ext3/4 or XFS, but not JFS
or ReiserFS),
and to force disks to write data immediately (known as direct
write) by turning off any hardware disk buffering/caching
(via hdparm -W 0), unless the disk uses a
non-volatile buffer.
Turn off any kernel buffering too!
(Otherwise the DBMS thinks the data has been written
when it may not have been; so crash recovery may lose/corrupt data!)
With ext3 or ext4 filesystems you can
control the journaling feature:
no journaling (write-through cache) with the mount option
data=writeback, ordered writes (only filesystem metadata
is journalled, but the by writing data then the metadata makes this
fairly safe) with the mount option data=ordered, and
journal (everything is journalled; safest but slowest) with the mount
option data=journal.
Best advice is to use journal mode and change to ordered only if
performance is bad and changing this seems to make a
difference.
Depending on how critical the data is, you may not want to use direct write as it slows down access to other files on that storage volume. With a decent UPS the small safety gain may not justify the performance loss. On the other hand an important DB shouldn't share a storage volume with other files; it should have one or more storage volumes of its own. Also consider that with SAN/NAS/external RAID/JBOD storage systems, you may not have control over this, and in any case there are many caches between the server's memory and the disk platter (the HBA, network switches, NAS head).
Once your data is safe then you can consider performance. Poor performance will result when using a DB on a filesystem, using default types and settings. A poorly tuned system can be much slower than a properly tuned one! The different can be between minutes and days to execute some query. For example using Oracle on a FAT32 or ext3/4 filesystems with RAID-5, when Oracle uses different block and stripe sizes, journals writes to its files, and possibly mirrors the tablespaces, is not going to be fast!
For most RDBMs the default OS value
for the disk read-ahead setting is too small,
usually 256 (= 128 KiB on older drives).
A good value should be 4096 to 16384.
To set on Linux, use either hdparm or
blockdev --setra (usually from
rc.local).
Next, mount the filesystem(s) with noatime.
These two measures are probably the most important ones to
improve performance.
Another measure is to enable file system Direct I/O by
mounting the file system with the right option
(e.g., --forcedirectio for UFS).
(File system Direct I/O will also disable
the read-ahead on some systems such as Solaris, but
may be useful anyway.)
Since most DBMSes have their own data and cache
buffers, using Direct I/O to disable the file
system buffer saves the CPU cycles from being
spent on double buffering.
Configure your system to use a swap disk or partition.
Most systems can use either a raw storage volume, or a file
to hold swapped-out pages.
Using a file will generally be slower than using a raw
storage volume.
(Note for Windows you don't have a choice; it uses the
file C:\pagefile.sys.)
The final OS tunable parameters to worry about are
for OS caching and swapping.
On Linux, set vm.swappiness to 0 (default: 60)
to make the system avoid swapping as much as possible.
To also help prevent swapping, set vm.overcommit_memory
to 2.
Lastly you can control how many dirty memory pages the
OS will allow to be outstanding before flushing them
to disk; too many and the delay when the flush does occur will be
noticeable, especially if you have lots of RAM.
You can set vm.dirty_ratio to 2 and
vm.dirty_background_ratio to 1 if you have more than
8 GiB of RAM.
(All of these settings can be changed using sysctl, or
directly using the /proc system.
Make sure you set these at boot time, either by editing
sysctl.conf or rc.local.)
Creating a separate partition and filesystem just for the DB files works better than creating those files in (for example) the root file system with lots of non-DB files. Using separate filesystems for indexes, table data, and transaction logs can also greatly improve performance, especially if the different filesystems are on different disk spindles.
Filesystems can also be tuned to applications.
For example, setting the block (cluster) size equal to a
DB block and a stripe size as a multiple of that
can increase DB performance if it uses a filesystem.
You should consider this if you can't change the DBMS's
block side (that is, the side of a disk read or write).
(For Linux, adjust the maxcontig parameter.)
This can have a big impact on system performance, particularly when
the DBMS is running a workload with a database size much
bigger than system memory.
However, it won't always have a large effect (but setting this
shouldn't hurt in any case).
Different types of filesystems work better with DBs than others. Using any FAT filesystem for a serious DB will cause poor performance. Using something like JFS or ext2 can improve performance at the cost of safety (not all writes are journalled). Using a journaling filesystem or RAID-1 (or similar) works best for DBs that don't do that internally anyway (but most do, with a transaction log file). Note that without filesystem journaling, the transaction log file can become corrupted in a crash. Using tablespaces you can put that log on one filesystem and the data on another.
Either use a faster filesystem type and RAID-0 and let the DBMS handle those issues, or tune the DBMS to not bother with journaling (except for the logs) and/or mirroring.
Performance also depends on the amount of writes versus reads for your application. Filesystems are typically designed have reads as fast as possible, and the difference in read and write speeds can be very noticeable. (Unfortunately there isn't much you can do about this, but I mention it so you can avoid using inappropriate benchmarks when comparing reported performance.)
Many enterprise-class DBMS (e.g., Oracle) don't require
a filesystem at all and can manage the raw disk space themselves.
This feature is often referred to as tablespaces
,
each of which can be thought of as a file holding the DB
data and meta-data.
(With PostgreSQL, tablespaces sit atop regular filesystems.)
Keep in mind monitoring and backups: If using a filesystem the DB gets backed up (and disk space gets monitored) by your normal filesystem tools and procedures. If using raw disk volumes then you must use your DBMS system to monitor and backup the data using a separate procedure. Have an appropriate backup policy (SLA) and restore procedures. Often a monitor process must be kept running too, for security, compliance auditing, and baselining purposes.
Choosing the proper filesystem types, creating the appropriate number of filesystems for your database, setting their options and mount options correctly, and settin the OS tunable parameters appropriately, can make a 5-fold or more difference in performance.
Once you've set up the filesystem and set the OS tunable parameters for safety and performance, it is time to tune the DBMS itself. Normally, that is left for a DBA to handle, not the system administrator. But there are some safety and performance measures you should always consider.
Before touching any tunable parameters, be sure you have a well designed schema that prevents anomalies (that is, in third normal form or better).
One of the most important steps to tuning a DB is to create a good set of indexes. Without proper indexes for you tables, many queries rely on sequential (linear) searching. Having too many indexes can also hurt performance, as the system must maintain all indexes whenever a table is updated. The primary key column(s) should be indexed (default for MySQL). Other columns may or may not benefit from indexing.
Different queries may get the same data but some will perform
better than others, for a given DB and
DBMS
You can use the SQL EXPLAIN statement
to see and compare the execution plans of various queries and
statements.
In addition most DBMSes collect statistics about
the use of various tables (and rows and columns), indexes,
and other database objects.
If available you can use the ANALYZE statment to
to see which indexes to drop or which tables could benefit
from additional indexes.
Beyond optimizing your schema, indexes, and queries, you can set tunable parameters for your DBMS. These vary widely between the different systems however. For best performance it usually pays to make sure you have the latest version of your selected DBMS installed and patched.
Another item to consider is setting the database cache size. If not adjusted for your amount of physical memory, the files used for the database will end up swapped to disk and the frequent dirty page writes will slow down the whole system.
You should consider setting the maximum number of concurrent database connections you will allow. The maximum value usually depends on network bandwidth and number of cores (or computers in a cluster) available. (Note for some commercial DBMSes the number of concurrent connections allowed depends on the license you purchased.)
MySQL tuning is considered, below. For tuning other DBMSes, you can usually find similar parameters. For PostgreSQL for example, see 5-Minute Introduction to PostgreSQL Performance.
The bottom line is for small or web site DBs that are mostly read-only, a filesystem based DB should be fine. For large OLTP systems you need to have the DBA and the system administrator work together to tune the disk layout, the filesystem types used, and the DBMS itself. If using some enterprise DBMS such as Oracle that handles much of what the filesystem and RAID system can do itself, using a raw disk volume (and properly tuned DB) will result in the greatest performance for OLTP systems.
MySQL Tuning
MySQL is a single-process, multithreaded application. The main thread is idle most of the time and "wakes up" every 300 milliseconds (msec) to check whether an action is required, such as flushing dirty blocks in the buffer pool. For each client request, an additional thread is created to process that client request and send back the result to each client once the result is ready.
MySQL includes several storage engines including MyISAM, ISAM, InnoDB, HEAP, MERGE, and Berkeley DB (BDB), but only InnoDB storage supports ACID transactions with commit, rollback, crash recovery capabilities, and row-level locks (with queries running as non-locking consistent reads) by default.
InnoDB also has the feature known as referential integrity with foreign key constraints support, and it supports fast record lookups for queries using a primary key. Because of these and other powerful functions and features, InnoDB is often used in large, heavy-load production systems. For simpler (e.g., PHP blog) applications one of the other, lighter-weight storage engines (with far fewer features and scalability) can provide superior performance. You can use different engines for different tables in the same database, to get the maximum performance and safety.
MySQL has peak performance when the number of connections equals roughly 4 times the number of CPUs. By estimating the number of concurrent connections, you can plan how large a SMP or cluster to use (i.e., how many DB servers are needed).
MySQL doesn't access the disk directly. Instead, it reads data into the internal buffer cache, reads/writes blocks, and flushes the changes back to the disk. If the server requests data available in the cache, the data can be processed right away. Otherwise, the operating system will request that the data be loaded from the disk.
The table_cache parameter controls the number of open
files (one table per file).
You should set this to
max-concurrent-connections * max-tables-per-join.
Note your OS must allow that many open files per process!
The default value is 64.
The other very important parameter to tune is
key_buffer_size, which defaults to 1 MiB, and controls
the size of the common cache used by all threads.
With >256MB of RAM, set to 64M at least.
Use the EXPLAIN query to see what MySQL
does.
Use this insight to see where to change queries and/or add
indexes.
Tuning your queries and adding the required indexes is the best
way to affect performance.
Some other tunable parameters can have a noticeable effect on the InnoDB engine:
The innodb_buffer_pool_size parameter determines the
cache size.
The bigger the cache size, the more disk accesses can be avoided.
The default value of 8 Mbytes is too small for most workloads.
You will need to increase this number when you see that
%b (percentage utilization of the disk) is
above 60%, svc_t (response time) is above
35 msec in the iostat -xnt 5 trace
output, and a high amount of read appears in the FILE IO part
of the show innodb status output.
However, you should not set the cache size too large, to avoid the
expensive paging for the other processes running without enough RAM,
because it will significantly degrade performance.
For systems running a single dedicated MySQL process only,
it should be fine to set the innodb_buffer_pool_size parameter
up to a value between 70 and 80 percent of memory since the footprint
of the MySQL process is only around 2 to 3 MiB.
For applications where the number of user connections is not tunable
(i.e., most of the time), the innodb_thread_concurrency
parameter can be configured to set the maximum number of threads
concurrently kept inside an InnoDB.
(Other threads are kept waiting their turn.)
If the value is too small under heavy load, threads will be kept
waiting and thus performance will suffer.
You need to increase this value when you see many queries waiting
in the queue in show innodb status.
Setting this value at 1000 will disable the concurrency checking,
so there will be as many threads concurrently running inside InnoDB
as needed to handle the different tasks inside the server,
but too many requests at once can also hurt performance.