Backups and Archives
Statistic: 94% of companies
suffering from a catastrophic data loss do not survive; 43% never reopen and
51% close within two years. (source)
Backups
are made for rebuilding a system that is identical to the current one. Backups are thus for (disaster-) recovery,
not transferring of data to another system.
They do not need to be portable.
In this sense, “backup” is used to mean a complete backup of an entire
system: not just regular files but all owner, group, date, and permission info
for all files, links, /dev
entries, some /proc entries,
etc.
Backups can be used not only for
“bare metal” backup and recovery, but also to install many identical
computers. Clonezilla allows you to do just that,
similar to the commercial product “Ghost”.
Clonezilla saves and restores only used blocks in the hard disk. This increases the clone efficiency. In one example, Clonezilla was used to clone
one computer to 41 other computers simultaneously. It took only about 10 minutes to clone a 5.6
GiB system image to all 41 computers via multicasting.
Archives
are for transferring data to other systems, operational (day-by-day, file-by-file)
recovery, or making copies of files for historical or legal/regulatory
purposes. As such, they should be
portable so that they may be recovered on new systems when the original systems
are no longer available. For example, it
should be possible for an archive of the files on a Solaris Unix system to be
restored on an AIX Unix, or even a Linux system. (Within limits, this portability should
extend to Windows and Macintosh systems as well.)
A backup has a
drawback for operational backup-and-restore needs. While backups enable rapid recovery and
minimal downtime in the event of a disaster, they also backup any
malware-infected or otherwise corrupted files.
You generally do not have more than one backup version of storage. Archives however, are made often and many
previous versions are available.
Most
of the time, the two terms are used interchangeably. (In fact, the above definitions are not
universally agreed upon!) In the rest of
this document, the term “backup” will be used to mean either a backup or an
archive as defined above. Most
real-world situations call for archives, since the other objects (such as /dev
entries) rarely if ever change on a production server once the system is
installed and configured. A single “backup”
is usually sufficient. For home users,
the original system CDs often serve as the only backup need; all other backups
are of modified files only and hence are “archives”.
Using RAID is not a replacement for regular backups! (Imagine a disaster such as a fire on your
site, an accidentally deleted file, or corrupted data.)
Service
Level Agreement (SLA)
Creating
backup policies (includes several sub-policies, discussed below) can be
difficult. Keep in mind the operational
backup requirements of the organization, often specified in an SLA or service
level agreement. Make sure
users/customers are aware of what gets backed up and what doesn’t, how to
request a restore, and how long it might take to restore different data from
various problems (very old data, a fire destroys the hardware, a DB record
accidentally deleted from yesterday, ...).
Statistics from
EMC.com:
·
80%
of restore requests are made within 48 hours of the data loss.
·
Around
15% of a storage administrator’s time is spent on backup and recovery.
·
Between
5% and 20% of backup/restore jobs fail.
·
In
2004, backup and recovery costs were about $6,000 per TB of data, per year.
(Show example SLA from Technion University.)
You
should know these related definitions, not just for backups but in general:
·
SLI —
A Service Level
Indicator is a measurable metric, whose values can be classified as
either good or bad. An example SLI for a
web service: 99% of all requests in a calendar year should have a response time
of under 200 ms.
·
SLA —
A service level agreement is a list
of SLIs that define the required behavior of some service. This should include all failure modes. Examples include what happens if the data
center loses power, or if available network bandwidth is exhausted.
·
SLO —
A Service Level
Objective is also a list of SLIs, but instead of listing guarantees it
lists the level of service you are aiming for.
For an SLA with the sample SLI from above, the SLO might be “99.99% of
all requests complete in 200 ms or less”.
(Often, SLAs are composed of several SLOs, rather than specific
SLIs.) See Wikipedia for
a good discussion of these terms.
The business world often uses many
acronyms with overlapping meaning.
Besides SLA and SLO, you may see references to RPO and RTO when
considering backups and recovery.
Recovery Point Objective (RPO) refers to the point in time in
the past to which you will recover. It
is the last point in time you did a backup.
Recovery Time Objective (RTO) refers to the point in time in the
future at which you will be up and running again. It is the time to restore.
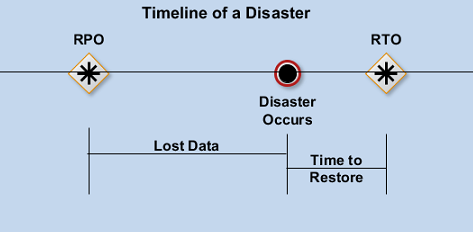
More frequent backups lead to smaller RPOs.
Some technologies such as disk-to-disk backups lead to smaller
RTOs. Both of these need to be specified
in an SLA.
Most
people underestimate how slow a restore operation can be. It is
often 10-20 times longer to restore a file than to back one up. (One reason: operating systems are usually
optimized for read operations, not write operations.)
An example SLA: Customers should be able to
recover any file version (with a granularity of a day) from the past 6 months,
and any file version (with a granularity of a month) from the past 3
years. Disk failure should result in no
more than 4 hours of down-time, with at worst 2 business days of data
lost. Archives will be full backups each
quarter and kept forever, with old data copied to new medium when the older
technology is no longer supported.
Critical data will be kept on a separate system with hourly snapshots
between 7:00 AM and 7:00 PM, with a midnight snapshot made and kept for a week. Users have access to these snapshots. Database and financial data have different
SLAs for compliance reasons.
Granularity refers to how often
backups are made. For example, suppose
backups are made each night at midnight.
If some user edits a file six times in the last two days, they can’t get
back any version; only the copy taken at midnight. In some cases, you want finer granularity (e.g., versions for each hour, or every single
version) and in other cases, coarser granularity
is fine (versions every month).
SLAs
vary considerably. For example, your
online sales system may require recovery granularity of one transaction, and
recovery time in seconds. Emails may
require per-email granularity for a day (or more) with recovery time in
minutes, and 24-hour granularity for older email. On the other hand, old business records (such
as stock-holder meeting minutes) can have granularity of days, and (except when
regulated) recovery time in days.
You must
also worry about security of your backups.
Have a clear policy on who is allowed to request a restore and how to do
so, or else one user might request a restore of other’s files. In some cases, this may be allowed by a
manager or auditor. (In a small
organization where everyone knows everyone, this is not likely to be a
problem.)
The backup process and backup server must
be made as secure as possible. Think
about it: the backup server needs remote root access to all your production
servers! If you automate backups, there is
not even a password to protect the process!
To
secure the backup server, do not use the server for anything else. Strip off unnecessary services and turn off
the ones you cannot remove. Harden that
server, and limit (incoming) access to SSH from a few internal IP
addresses. Create a user (and group)
just for the backup process to use.
To
keep the process secure, have the backup process connect to the remote machines
using an SSH key. (The key cannot be
password protected if you wish to automate (have unattended) backups.) On the hosts to be backed-up, add the backup
user with SSH key authentication only.
Next, use SSH features to prevent that user from running any program
except the backup software. That backup
software will need root access. The best
way (if possible) is to have that software run sudo
to run the piece that actually needs to read the protected files. Finally, configure sudo to allow the backup user only to run (as root) that
one command.
Types and Strategies of Backups and Archives
It is possible to backup only a portion of the files
(and other objects in the case of a backup) on your systems. In fact, there are three types of backups (or
archives):
1.
Full (also known as “epoch” or “complete”) -
everything gets backed-up.
2.
Incremental - backup everything that has been
added or modified since the last backup of any type (either incremental or
full).
3.
Differential - backup everything that has been
added or modified since the last full backup.
Differentials can be assigned levels: level 0 is a full
backup and level n is everything that has changed since the
last level n-1 backup.
(Differential is sometimes called cumulative.)
(Many
people don’t bother to distinguish between incremental and differential.) A system administrator must choose a backup
strategy (a combination of types) based on several factors. The factors to consider are safety, required
down time, cost, convenience, and speed of backups and recovery. These factors vary in importance for
different situations. Common strategies
include full backups with incremental backups in-between, and full
backups with differential backups in-between (a two-level
differential). Sometimes a three-level
differential is used, but rarely more levels.
(You rarely use both incremental and differential backups as part of a
single strategy.) The strategy of using
only full backups is rarely used.
What
with modern backup software, the differences between the strategies mentioned
above aren’t that large. Incrementals
take less time to backup and more time to restore (since several different
backup media may be needed) compared with differential backups (where at most
two media, the last differential and the last full backup media, are used to
recover a file). Full backups take a
huge amount of time to make but recovery is very fast. (Example: disk corruption on the 25th of the
month: recovery is last full then last
differential, or last full then 24 daily incrementals.)
Most
commercial software keeps a special file that is reset for each full backup and
keeps track of which incremental tape (or disk or whatever) holds which
files. This file is read from the last
incremental tape during a restore, to determine exactly which tape to use to
recover some file. Such information is
known as backup metadata, or the
backup catalog.
Backup Metadata contains information about what has been backed
up, such as file names, time of backup, size, permissions, ownership, and most
importantly, tracking information for rapid location and restore. It also
indicates where it has been stored, for example, which tape.
When devising a backup strategy, it is critical to understand the
nature of the data and the nature of changes to the data. Granularity levels depend on several
considerations. What is the aggregate
weekly data change rate? If the change
rate were close to or greater than 100% (daily change about 20%), it makes
little sense to use an incremental backup, because the overhead for deciding
which files need to be backed up may be longer than the time it takes fora full
backup.
Another consideration is
file size. Some applications use larger
files than others. An environment with
such applications tends to have a larger data change rate, because even a small
change to the data results in the whole file being changed. The larger the average file size, the greater
the percentage of the data set. Other
applications, like software development, use many smaller files. The rate of change in these environments can
be much lower. In such environments, the
more mature the data set, the lower the change rate.
Another factor to consider
is the properties of the files in your backup set. For instance, are they natively compressible? if not, the negative impact compression has
on performance makes it less desirable.
The Backup
Schedule
The
frequency of backups (the backup schedule) is another part of the
policy. In some cases, it is reasonable
to have full backups daily and incremental backups several times a day. In other cases, a full backup once a year
with weekly or monthly incremental backups could be appropriate. A common strategy suitable for most corporate
environments would be monthly full backups and daily differential backups. (Another example might be quarterly full
(differential level 0) backups, with monthly level 1 differentials, and daily
level 2 differentials.) However more
frequent full backups may save tapes (as the incremental backups near the end
of the cycle may be too large for a single tape).
Note
that in some cases there will be legal requirements for backups at certain
intervals (e.g., the SEC for financial industries, the FBI for defense
industries, or regulations for medical/personal data). Depending on your backup software, it may be
required to bring the system partially or completely off-line during the backup
process. Thus, there is a trade-off
between convenience versus cost, versus the safety of more frequent backups.
In
a large organization, it may not be possible to perform a full backup on all
systems on the same weekend; there is usually too much data to backup in the
time window provided. A staggered schedule is needed, where (say) 1/4 of the servers get backed
up on the first Sunday of the month, 1/4 the second Sunday, and so on. Each server is still being backed up monthly
but not all on the same day of the month.
Be aware that small changes to the schedule can result in dramatic changes in the
amount of backup media needed. For example,
suppose you have 4GB to backup within this SLA: full backup every 4 weeks (28
days) and differential backups between.
Now assume the differential backup grows 5% per day for the first 20
days (80% has changed) and stays the same size thereafter. Some math reveals that doing full backups
each week (which still meets the SLA) will use a third the amount of the tape
of a 28-day cycle, in this case.
Good
schedules require a lot of complex calculation to work out (and still meet the SLAs). Modern backup software (such as Amanda) allows
one to specify the SLA and will create a schedule automatically. A dynamic schedule will be adjusted
automatically depending on how much data is actually copied for each
backup. Such software will simply inform
the SA when to change the tapes in a jukebox.
On
a busy (e.g., database) server downtime will be the most critical factor. In such cases consider using LVM snapshots,
which very quickly makes a read-only copy of some logical volume using very
little extra disk space. You can then
backup the snapshot while the rest of the system remains up.
Another
strategy is called disk-to-disk-to-tape,
in which the data to be backed up is quickly copied to another disk and then
written to the slower backup medium later.
Sometimes different applications require
independent backup of their data for various reasons (such as different
security, retention, or SLA requirements).
Examples include servers versus PCs, mobile devices (laptops and smart
phones), different databases, email, log data, and so on. Even the backup procedures may be
different. For example, an LVM snapshot
won’t correctly backup a database that was in the middle of some operation or
had data cached in memory at the time.
Policy questions
that should be answered by SLA:
·
What
are the restore requirements – granularity (what points in time can be
requested), and time for various types of recovery?
·
Where
and when will the restores occur?
·
What
are the most frequent restore requests?
·
Which
data needs to be backed up?
·
How
frequently should data be backed up (hourly, daily, weekly, monthly), and with
what strategy (full, differential, incremental)?
·
How
long will it take to backup?
·
How
many copies to create?
·
How
long to retain backup copies?
Other Policies
Deciding
what to backup is part of your policy too. Are you responsible for backing up the
servers only? Boss’ workstation? All workstations? (Users need to know!) Network devices (e.g., routers and
switches)? It may be appropriate to use
a different backup strategy for user workstations than for servers, for
different servers, or even different partitions/directories/files of servers.
An often-overlooked item is the
MBR/GPT. Make a copy of it with:
dd if=/dev/sda of=/tmp/MBR.bak bs=$SECTOR_SIZE count=1
Another
part of your backup policy is determining how long to keep old backups
around. This is called the backup
retention policy. In many cases,
it is appropriate to retain the full backups indefinitely. In some cases, backups should be kept for 7
to 15 years (in case of legal action or an IRS audit). In some cases, you must not keep certain data
for too long or you may face legal penalties.
Such
records are often useful for more than disaster recovery. You may discover your system was compromised
months after the break-in. You may need
to examine old files when investigating an employee. You may need to recover an older version of
your company’s software. Such records
can help if legal action (either by your company for by someone else suing your
company) occurs.
Since
Enron scandal (2001) and Microsoft scandals (when corporate officers had emails
subpoenaed by DoJ), a common new policy is “if it doesn’t exist it can’t be
subpoenaed!” These events may have led
to this revision of the FRCP:
FRCP — the Federal Rules of Civil Procedure
These include rules for handling of ESI (Electronically Stored Information) when legal action (e.g.
lawsuits) is immanent or already underway.
You must suspend normal data
destruction activities (such as reusing backup media), possibly make
“snapshot” backups of various workstations, log files, and other ESI, classify
the ESI as easy or hard to produce, and the cost to produce
the hard ESI (which the other party must pay), work out a “discovery” (of
evidence) plan, and actually produce the ESI in a legally acceptable
manner. An SA should consult the corporate
lawyers well in advance to work out the procedures.
It
is important to decide where store the backup media (storage
policy/strategy). These
tapes or CDs contain valuable information and must be secured. Also, it makes no sense to store media in the
same room as the server the backup was made from; if something nasty happens to
the server, such as theft, vandalism, fire, etc., then you lose your backups
too. A company should store backup media
in a secure location, preferably off-site.
A bank safe-deposit box is usually less than $50 a year and is a good
location to store backup media. If
on-site storage is desirable, consider a fire-proof safe. (And keep the door shut all the time!) Consider remote storage companies but beware
of bandwidth and security issues.
Different storage methods
offer different levels of accessibility, security and cost for your backup
data:
·
Online storage: Sometimes called
secondary storage, online storage is typically the most accessible type of data
storage. A good example would be a large
disk array. This type of storage is very
convenient and speedy, but is relatively expensive and vulnerable to being deleted
or overwritten, either by accident, or in the wake of a data-deleting virus
payload. (HCC has an online storage site
in Lakeland.)
·
Near-line storage: Sometimes called
tertiary storage, near-line storage is typically less accessible and less
expensive than online storage. A good
example would be an automatic tape library. Near-line storage is used for archival of
rarely accessed information, since it is much slower than secondary storage.
·
Offline storage: An example of offline
storage is a computer storage system which must be driven by a human operator
before a computer can access the information stored on the medium. For example, a media library system which
uses off-line storage media, as opposed to near-line storage, where the
handling of media is automatic.
·
Off-site vault: To protect against a
disaster or other site-specific problem, many people choose to send backup media
to an off-site vault. The vault can be
as simple as the system administrator’s home office or as sophisticated as a
disaster hardened, temperature controlled, high security bunker that has
facilities for backup media storage.
In
most cases, a mix of storage methods can be the most effective storage
strategy.
Media
Replacement Policy (a.k.a. Media Rotation Policy)
Backup
media will not last forever. Considering
how vital the backups might be, it is a false economy to buy cheap tape or
reuse the same media over and over. A
reasonable media replacement policy
(also known as the media rotation schedule) is to use a new tape a fixed number of times, then toss
it. The rotation schedule/replacement
policy can have a major impact on the cost of backups and the speed of
recovery.
Before
using new media for the first time, test it and give it a unique, permanent
label (number). Annual backup tapes could be duplicated just in case the original
fails.
There
are many possible schemes for media rotation. A simple policy is called incremental
rotation which means different things to different folks. Basically, you should number the media used
for a given cycle, such as D1–D31 for the 31 tapes used for daily backups. After one complete cycle (with each tape used
once), the next cycle uses tapes D2–D32; tape D1 gets re-labeled as M1. The 12 monthly tapes M1-M12 are each used
once, then M2-D13 is used the following year, etc. The old M1 tape becomes permanently retired
(or archived). Thus, a given tape will
be used 31 times for daily, 12 times for monthly, and once for yearly backups,
a total of 43 uses before you need to replace it.
One of the most popular schemes is called
grandfather, father, son (GFS) rotation.
(This term predates political
correctness.) This scheme uses daily
(son), weekly (father), and monthly (grandfather) backup sets. In each set, the oldest tape is used for the
next backup. Here’s an illustration
(from mckinnonsc.vic.edu.au/vceit/backups/backup_schemes.htm):
• Monday - daily backup to tape #1
• Tuesday - daily backup to tape #2
• Wednesday - daily backup to tape #3
• Thursday - daily backup to tape #4
• Friday - weekly to tape #5. This tape is called Week 1 Backup.
(Of
course, you can extend this idea to seven-day schemes as well.)
The
next Monday through Thursday you would re-use tapes #1 through #4 for the daily
backup set. But next Friday you do
another weekly backup to Week 2 backup (tape #6). Week 3 is the same as week 2, using Week 3
backup (tape #7) on Friday. Tapes 5–7
form the weekly backup set.
At
the end of the fourth week do a monthly to Month 1 backup tape (tape #8). At the end of the fifth week, Week 1 tape is
re-used.
So,
the daily tapes are recycled weekly. The
weekly tapes are recycled monthly.
Monthly tapes are recycled annually.
Each year a full annual backup is kept safely stored and never re-used.
Clearly,
the daily tapes (tapes 1–4) are used much more often than the weeklies (tapes
5–7) and monthlies (tapes 8–∞). This
will mean they will suffer more wear and tear and may fail more readily.
The
incremental scheme can be used with any rotation policy, such as GFS or Towers
of Hanoi. A tape (e.g. tape 1) will be
used as a weekly tape after a month (or two or more) of daily use. After a year (or two or more) of weekly use,
it can be error-checked (in case it’s becoming unreliable) and will be used as
a monthly tape. After 12 (or 24 or more)
uses as a monthly tape it could be “retired” as a permanent yearly backup tape.
Most
software that automates backup uses the tower of Hanoi
method, which is more complex but does result in a better policy.
{kind=link}
Class discussion:
Determine backup policies for YborStudent server.
One possibility: Full backup
(level 0) of /home one per term, level 1 once per month, level 2 each day. The SLA will specify a recovery time of a
maximum of 2 working days. Backups should
be kept for 6 months after the end of the semester.
For
security reasons, you should completely erase the media before throwing the
media in the trash. (This is harder than
you think!) An alternative is to shred or burn old media, and/or encrypting backups
as they are made.
The time for a restore depends if
incremental or differential backups are done for daily and weekly. In this scheme, the monthly backup is usually
a full backup, but doesn’t need to be if you use a 4 or 5 level differential
backup scheme.
Backup Media Choices
There are too many choices
to count today. For smaller archives,
flash or other removable disks, writable CD-ROMs or DVDs, (These are WORM
media) and old fashioned DLT, DAT, DDS-{2,4,8,16} tape drives were
popular. (I used a DDS-2 SCSI drive at
home.) While using tape for backups is
no longer popular for consumers, it is more popular than ever for the
enterprise, especially those with enormous amounts of data to backup.
Consider LTO (linear tape open) drives. These are fast (for tape: they max out at 800
MiB/S) and have a very low cost per byte.
LTO tapes have a range of densities; LTO4 tapes can hold up to 1.6 TB
each; the current (2019) standard, LTO7, holds 6 TB per tape, with a shelf life
of 30-50 years, and costs around $50 to $75 each. An auto-loader LTO7 drive can cost around
$6,000; a cheap drive is still around $2,700 (2020).
LTO formats change every few
years, and an LTP-n drive can only
work with LTO-n, n-1, or n-2 tapes. So every 5-8 years, old data must be migrated
to the newest format. This gets
expensive and can be time-consuming as well.
Tape storage is very
cheap, typically less than $20 for 80 gigabytes of storage. (DDS-2 tapes cost about $7 and hold 4 GB
each. DDS-4 tapes are fast backups and
hold ~100GB each.) However, tapes and
other magnetic media can be affected by strong electrical and magnetic fields,
heat, humidity, etc. Also, the higher
density tapes require more expensive drives (some over $1,000). LTO tape delivers a 2x - 4x savings in
operational costs over SSD backup.
In 2010, the record for how much
data magnetic tape could store was 29.5GB per square inch. To compare, a quad-layer Blu-ray disc can hold
50GB per disk. Magnetic tapes can be hundreds of feet long. In 2014, Sony announced that it developed new
magnetic tape material that can hold 148GB per square inch. With this material,
a standard backup tape (the size of an old cassette) could store up to 185TB. To hold the equivalent amount of data would
take 3,700 dual-layer 50GB Blu-rays (a stack that would be over 14 feet tall).
— extremetech.com
Today (2018), the density of tape
storage continues to grow, doubling about every two years.
Compared to hard disks,
tape is more reliable (reportedly 1,000 times or more fewer errors), takes zero
power to store, and when off-line (unmounted), it is extremely safe from
hackers or errors. Modern tape backup
units can write data faster than disks can, and can hold much more data. And of course, tape is cheap. Recently (2018), IBM announced a new tape
prototype than can hold over 300 TiB on a single tape! The only downside is that to recover the data
from tape takes much longer (seconds/minutes) compared to disk
(microseconds/milliseconds).
Large data centers such as Google
and Microsoft Azure cloud use both disk and tape backups: disk backup at
different locations for quick recovery of some errors, and tape backup for
safety. (For example, in 2011 Google lost
thousands of emails from all disks due to a software bug, but was able to
eventually restore all the lost data from their tape backups.)
An external hard drive (less than $100 for 1TB) connected directly
to your PC can use the backup program that comes with your operating system (Backup and Restore Center on Windows,
and Time Machine on OS X). Most backup software can automate backups of
all new files or changed ones on a regular basis. This is a simple option if you only have one
PC.
Optical
media such as CDs are durable and fairly cheap but take much longer to write. They can be reused less often than magnetic media
and are still susceptible to heat and humidity.
Optical media can scratch if not carefully handled. Also consider the bulk of the media. If you must store seven years’ worth of
backups, it may be important to minimize the storage requirements and
expense. A CD-ROM can hold about 700 MiB
while a dual-layer Blu-ray can hold 50 GiB.
However, if stored and handled correctly, such media can hold data
without any maintenance for many decades at least.
A
choice becoming popular (since 2008) is on-line
storage, e.g., HP Upline, Google GDrive, etc. (for SOHO, Mozy or
BackBlaze). (This market changes rapidly
so do research on current companies.)
The companies offer cheap data storage and complete system backups,
provided you have a fast Internet connection.
Many colocation facilities (“colos”, usually at network exchange points)
provide this service as well to the connected ISPs. If you go this route, make sure all the data
is encrypted using industry standard encryption at your site before
transmission across the Internet. (Never
use any company that uses “proprietary” encryption regardless of how secure
they claim it is!) The major danger to
this method is the company may not follow best practices to keep data safe and
intact, or may simply go out of business without notice.
When
backing up large transaction database files, the speed of the media transfer is
important. For instance, a 6 Mbps
(Megabits per second) tape drive unit will backup 10 gigabytes in about 3 hours
and 45 minutes. (In most cases
incremental or differential backups contain much less data!)
For legacy IDE controllers, you
only choice is a TRAVAN backup drive.
Very slow, don’t use! For SCSI
drives (such as DDS drives from HP) there are two speeds for the SCSI
controller, depending on what devices are on it. A tape drive will slow down the SCSI bus by
half, so consider dual SCSI controllers.
For
networks, consider a networked backup unit. This would allow a single backup system to be
used with many different computers. Thus,
you can buy one high-speed device for about the same money as several
lower-speed devices. Keep in mind
however that a network backup can bring a standard Ethernet network to its
knees. (The network only shares 10 Mbps
for all users on a SOHO or wireless LAN.)
Even a Fast Ethernet (100 Mbps) LAN might suffer noticeable delays and
problems.
An
excellent choice for single-system backup is a USB disk. Also using SAN/NAS to centralize your storage
makes it easy to use a single backup system (robot tapes).
It
is a good idea to have a spare media drive (e.g., DLT tape drive), in
case the one built into a computer fails when the computer fails. This is especially true for non-standard
backup devices that may not be available from CompUSA on a moment’s
notice. Regularly clean and maintain
(and test) your backup drives.
(While
I don’t know of any organization that does this, consider copying old data to
new hardware once the old drives are no longer supported or available. If you don’t have a working drive (including
drivers), the old backups are useless!)
In the end, most backups still use
tape as the most cost-effective solution.
Keep in mind that restore from tape can be a very slow, manual process;
it may require mounting several tapes to recovery a single file! And if tapes are stored off-site, it may take
a day or more just to ship them back to you.
Backup to disk is becoming more
popular as the costs of disks go down.
As
you can see, many factors must be considered when designing a backup system and
its policies. In addition to the ones
mentioned earlier, you need to consider the total amount of data to be backed up,
total amount to retain, removing old and/or unneeded data, and
sanitizing/blinding/anonymizing data that is to be used for reports, research,
or training.
Keeping
management reports can help answer these questions. Suppose you guessed to keep email backups for
3 months. That’s expensive, but is that
too long or too short? An internal study
at EMC.com in 2007 determined that for them, over 25% of restore requests were
for the same day’s data, and fully 100% of email restore requests were made in
two weeks or less after losing email.
Without regulatory/legal requirements in their case, they changed the
policy and saved a considerable amount of money and effort.
Archival Storage
Magnetic
media is not a good choice for very long term, or archival backups. The reason is, over time such media is
subject to bit rot: loss of data
just from sitting around, even unpowered.
How can this happen?
Hard
drives use magnetism to store bits of data in disk sectors. These bits can “flip” over time for many
reasons, which can lead to data corruption. To mitigate this, hard drives have
error-correcting code (ECC) that can sometimes correct flipped bits. However, if enough bits flip then corruption
will occur. This will take time; some hard
drives have the potential to last with their data intact for decades even if
powered down.
Solid-state
drives don’t have any moving parts like hard drives. These drives use an insulating layer to trap
charged electrons inside microscopic transistors to differentiate between 1s
and 0s, in groups (“rows”). Over time, the
insulating layer degrades and the charged electrons leak out, thus corrupting
data. Powered down, an SSD will see bit
rot occur within a few years.
If
using such devices for archival backup, it’s a good idea to power them up
periodically and let them run fsck. For a hard drive, you should power it up at
least once every year or two to prevent the mechanical parts of the drive from
seizing up. You should also “refresh”
the data by recopying it or use a third-party tool like DiskFresh (which reads
then writes each block, checking for bad blocks as it goes). SSDs are a little simpler since they just need
to maintain their charge. You can power
them up for a few minutes about twice a year, but I still recommend using some
tool to check for bad rows.
Even
if you kept your backups powered up all the time, bit rot can occur!
Your
best choice for archival storage is likely LTO tape if you can afford it. Otherwise, consider optical media for this.
Enterprise Backup Systems
Most
enterprise-wide backup systems are designed with a client-server
architecture. Each host holding data to
be backed up runs a backup client, known as a backup agent. This agent communicates with the (dedicated) backup
server. Each backup agent can
send messages to, or answer queries from, the backup server.
The
server maintains the backup metadata (such as the catalog of what is backed up
onto which tapes). In addition, the server
sends commands to the agent to gather data and return it, when performing an
actual backup operation.
Typically,
the backup server is also connected with one or more storage nodes. which is
the hardware/software responsible to reading and writing to/from the backup
media.
If
your organization does not use a SAN for the data, the clients communicate with
the server through your network. Network
backup can be dangerous, as the network capacity may not be sufficient,
or may cause timeouts and excessive latency for other applications using the
network at the same time. It’s even
worse when the storage nodes are not directly attached to the backup
server. Proper backup systems will limit
their network utilization and use a staggered schedule.
If
you do have a SAN, you attach storage nodes to it and run the server there; no
backup data needs to travel on the network (but backup metadata will). If the storage node isn’t directly connected
to the SAN unit, it connects through the dedicated storage network (e.g.,
FibreChannel), which should not cause any utilization or latency problems.
In
a smaller setup, direct attached backup can be used to back up data from a
single client. The agent and server are
just one application, running on the client, and the storage node is also
directly attached to the client.
Since
tape storage nodes are slow to read and especially slow to write, today many
systems put a disk between the backup server and the slower storage node.
Consumables Planning (Budgeting)
Suppose
a medium to large organization uses 8 backup tapes a day, 6 days a week, means
48 tapes. If your retention policy is to
keep 6 months’ worth of incrementals, that’s 1,248 tapes needed. High capacity DLT tapes might go for $60, so
you would need $74,880.00. In the second
part of the year, you only need new tapes for full backups, an additional 260
tapes (say) for $15,600, or more than $90k for the first year ($7,500 per
month). (Not counting spares or the cost
of drive units.) Changes to the policies
can result in expense differences of over $1000 per month!
As
backup technology changes over the years, it is important to keep old drives
around to read old backup tapes when needed.
You should keep old drives around long enough to cover your data
retention policies.
Try
to avoid upgrading your backup technology (drives, tapes, software) every few
years, or you’ll end up with many different and incompatible backup tapes. Note the budget must include amortization of
the drive expenses.
Tools for Archives and Backups
Archives
are easier to make than backups, so most tools create archives. A tool cannot make a “backup” without knowing
the underlying filesystem intimately, i.e. it must parse the filesystem on
disk. The reason is twofold:
·
Different filesystems exhibit different
semantics. No single tool supports all
the semantics of all filesystem types.
You need a different backup tool per FS type.
·
The kernel interface obfuscates information
about the layout of the file on disk.
You have to go around the kernel, direct to the device interface, to see
all the information about a file that is necessary for recording it correctly.
If
you want to store the kernel’s view of files along with all of the semantics
the filesystem provides and none of the non-filesystem objects that might
appear to inhabit the filesystem (such as sockets or /proc entries), use
the native dump program (and restore)
provided by your vendor specifically for that purpose (whatever they name it),
for your filesystem type (note for Reiser4Fs you can just use star).
dump uses /etc/dumpdates to track dump levels
(that is, dump supports
differential backups). Some of the
differences between dump (for backups) and tar, cpio, or pax
for archives are:
1.
dump is not confused by object types that the
particular operating system has defined as extensions to the standard
filesystem; it also does not attempt to archive objects that do not actually
reside on the filesystem, e.g. doors
and sockets. Consider what GNU tar does to
UNIX-domain sockets: it archives them as named pipes. They are not on the filesystem, so they
should not be archived at all. dump
handles this situation correctly.
2.
tar ignores extended attributes (and ACLs unless you
use the --acls or the --xattrs option when creating, adding
to, or extracting from, the archive), while a native dump program will
correctly archive them. (A new
extensible backup format known as pax will archive ACLs, SELinux labels,
and other meta-data stored in extended
attributes. A tool called star uses a similar format. Find out about star on the web.)
3.
tar cannot detect reliably where holes
are. dump is not confused by files
with holes (such as utmp); it
will dump only the allocated blocks and restore will reconstruct the
file with its original layout.
4.
tar uses normal filesystem semantics to read files. That means it modifies the access times
recorded in the filesystem inodes,
when extracting files. This
effectively deletes an audit trail which you may require for other
purposes. (Modern Gnu tar has extra options to handle this
correctly.) dump parses and
records the filesystem outside of kernel filesystem semantics, and therefore
doesn’t modify the filesystem in the process of copying it.
Not
all filesystem types support dump
and restore utilities. When picking a filesystem type, keep in mind
your backup requirements.
GNU tar
is a popular tool for archiving the user’s view of files. Another standard choice is cpio,
rarely used anymore. Note neither tool
is standardized by POSIX. A new standard
tool, based on both (and hopefully better than either) is pax. These, combined with find and some
compression program (such as gzip or bzip2) are used to make portable
archives.
You
can ask find to locate all files
modified since a certain date and add them to a compressed tar archived created on a mounted
backup tape drive. A backup shell script
can be written, so you don’t end up attempting to backup /dev
or /proc
files. (See backup script on web
page.) (Note! Unix tar ≠ GNU tar; use the GNU version.
Unix tar doesn’t handle
backups that require multiple tapes.)
For either backups or archives, use crontab to schedule backups
according to the backup schedule
discussed earlier. (Show ls -d /etc/*cron*.) If your company prefers to have a human
perform backups, remember that root
permission will be needed to access the full system. Often the backup program is controlled by sudo
or a similar facility, so the backup administrator doesn’t need the root
password.
The
find
command can be used to locate which files need to be backed-up. Use “find / -mtime
-x”
for incrementals and differentials to find files changed since x (you can store x as a timestamp on files, for example /etc/last-backup.{full,incremental,differential}
). Use find
with Gnu tar
roughly like this:
mount
/dev/removable-media /mnt
find / -mtime -1 -depth |xargs tar -rf --xattrs
\
/tmp/$$
gzip /tmp/$$; mv /tmp/$$.gz /mnt/incremental-6-20-01
touch /etc/last-backup.incremental
umount
/dev/removable-media
(Instead
of “-mtime -1” to mean less than 24 hours ago, you
can use “-newer x”,
where x
is some file.)
Commercial
software is affordable and several packages are popular for Unix and Linux
systems, including “BRU” (www.BRU-Pro.com), VERITAS, Seagate’s BackupEXEC, and
“Arkeia” (www.arkeia.com). (I haven’t
used these; I just use tar and find.)
Of
course, there are free, open source choices as well, such as KDE ark, or amanda (network backups). One of the best is BackupPC. Another is Bacula
(or Bareos, a fork of the original). Some of these can create schedules, label
tapes, encrypt tapes, follow media rotation schedules, etc.
Be careful of bind mounts and private
mounts when performing backups, especially when using home-grown scripts
that use find, tar, etc.! Tools such as Bareos will detect symlinks and
bind mounts and not “descend into” those, but not all tools will (or may not by
default). Bareos backs up the symlink,
not duplicates of the files.
In addition, bind mounts are only
known to the kernel, in RAM, and are never backed up; you need to list those in
fstab to restore those “views”.
Finally, if you don’t run the
backup with root privilege, you may only back up the polyinstantiated (a per-user “private view”) part of a directory
that the process can see.
The most important tool is the documentation:
the backup strategy, media types and rotation schedule, hardware
maintenance schedule, location of media storage (e.g., the address of the bank
and box number), and all the other information discussed above. This information is collectively referred to
as the backup policy. This
document should clearly say to users what will be backed up and when, and what
to do and who to contact if you need to recover files.
Note: Whatever tools you use, make sure you test
your backup method by attempting to use the recovery procedure. (I know someone who spent 45 minutes each
working day doing backups for years, only to realize none of the backups ever
worked the first time he attempted to recover a file!)
(Parts
of this section were adopted from Netnews (Usenet) postings in the newsgroup “comp.unix.admin” during 5/2001 by
Jefferson Ogata. Other parts were
adopted from The Practice of System and
Network Administration, by Limoncelli and Hogan, ©Addison-Wesley.)
Backups with
Solaris Zones and Other Containers
Solaris zones, Docker
containers, and similar technology contain a complication for backup: many
standard directories are actually mounted from the global zone via LOFS
(loopback filesystem). These should only
be backed up from the global zone. The
only items in a local zone needing backup (usually) are application data and
configuration files. Using an archive
tool (such as cpio, tar, or star)
will work best:
find
export/zone1 -fstype lofs -prune -o -local \
| cpio -oc -O /backup/zone1.cpio
Whole zones can be fully or
incrementally backed up using ufsdump. Shut down the zone before using the ufsdump command to put the zone in a
quiescent state and avoid backing up shared file systems, with:
global#
zlogin -S zone1 init 0
Solaris supports filesystem
snapshots (like LVM does on Linux) so you don’t have to shut off a zone. However, it must be quiesced by
turning off applications before creating the snapshot. Then you can turn them back on and perform
the backup on the snapshot: Create it
with:
global# fssnap -o
bs=/export /export/home #create snapshot
global# mount -o ro /dev/fssnap/0 /mnt
# then mount it.
You should make copies of
your non-global zones’ configurations in case you have to recreate the zones at
some point in the future. You should create the copy of the zone’s
configuration after you have logged into the zone for the first time and
responded to the sysidtool
questions:
global# zonecfg -z zone1 export > zone1.config
Adding a backup
tape drive
Added
SCSI controller (ADAPTEC 2940)
Added
SCSI DDS2 Tape drive
On
reboot kudzu detected and configured SCSI controller and tape device
Verify
devices found with ‘dmesg’:
indicate tape is /dev/st0 and /dev/nst0
Verify
SCSI devices with ‘scsi_info’ (/proc/scsi)
Verify
device working with: mt -f /dev/st0
status
Create
link: ln -s /dev/nst0 /dev/tape
Verify
link: mt status
Note:
/dev/st0 causes automatic tape
rewind after any operation, /dev/nst0
has no automatic rewind, but most backup software knows to rewind before
finishing. If you plan to put multiple
backup files on one tape, you must use /dev/nst0.
Common Backup
and Archive Tools:
mt
(/dev/mt0, /dev/rmt0)
st
(/dev/st0, /dev/nst0 - use nst for no auto rewind)
mt and rmt
(remote tape backups); use like: mt -f /dev/tape
command, where command is one
of: rewind, status, erase,
retention, compression, (toggle compression
on/off), fsf count
(skip forward count files), eod (skip to end of data), eject, ...
dump/restore (These operate on the drive as
a collection of disk blocks, below the abstractions of files, links and
directories that are created by the file systems. dump
backs up an entire file system at a time.
It is unable to backup only part of a file system or a directory tree
that spans more than one file system.)
tar, cpio,
dd, star
(and pax and spax)
A
comparison of these tools (Note Gnu tar has stolen most of the good ideas from
the other tools, accounting for its popularity):
·
cpio
has many more conversion options than tar
and supports many formats, but is a legacy tool rarely used today. Gnu cpio
does not support the pax
format. (Use “-H ustar”.) The default format used has many problems on
modern filesystems, such as crashing with large inode numbers
·
cpio
can be used as a filter, reading names of files from stdin. (Gnu tar
has this ability too.)
·
On restore, if there is corruption on a tape tar will stop at that point. cpio
will skip over corruption and try to restore the rest of the files.
·
cpio
is reportedly faster than tar
and uses less space (because tar
uses 512-byte blocks for every file header, cpio
just uses whatever it needs only).
·
tar
supports multiple hard links on FSes that have 32-bit inode numbers, but cpio can only hand up to 18 bits in the default format (which can be
changed with “-H”).
·
tar
copies a file with multiple hard links once, cpio
each time.
·
Gnu tar
can support archives that span multiple volumes; cpio
can too but is known to have some problems with this.
·
Modern tar
(star)
supports extended attributes, used for SE Linux and ACLs. cpio
doesn’t in the default format.
·
pax is POSIX’s answer to tar and cpio
shortcomings. pax attempts to read and write many of the various cpio and tar formats, plus new formats of its own. Its command set more resembles cpio than tar; with find
and piping, this makes for a nicer interface.
To use extended attributes (including SE Linux labels) and ACLs, the “pax” archive format (or equivalent)
must be used and not all systems support this (POSIX required) format. Check available formats with “pax -x
help”. Use star
or spax instead, if necessary. (Note the LSB requires both pax and star.)
·
dd
is an old command that copies and optionally converts data efficiently. It can convert data to different formats,
block sizes, byte orders, etc. It isn’t
generally used to create archives, but is often used to copy whole disks or
partitions (to other disks/partitions when the geometry is different), copy
large backup files, to create remote archives (“tar
...|ssh ... dd ...”), and to copy and create image
files. (The command was part of the ancient
IBM mainframe JCL utility set (and has a non-standard syntax as a result); no
one knows anymore what the name originally meant.)
There are two caveats to using dd
to copy disks (or disk images): If the
source and destination drives have different sector sizes (e.g. 512 and 4096
bytes per sector), using dd
won’t work well because partition tables (MBR or GPT) contain positions and
sizes in sector counts; you’d need to manually overcome that somehow. Secondly, unless the source and destination
drives have the exact same size, the GPT backup partition table won’t be copied
to the right location (the very end) on the destination drive; the extra space
after that won’t be usable. Using tools
such as gparted can account for
such issues.
libarchive is a portable library for any
POSIX system, including Windows, Linux, and Unix, that provides full support
for all formats. Currently it includes
two front-end tools built with it: bsdtar and bsdcpio. These will support extended attributes and ACLs,
when used with the correct options and with the “pax” (and not the default “ustar”) format.
There
are two variations of standard dd
worth mentioning. Gnu ddrescue is designed
to rebuild files from multiple passes through a corrupted filesystem and from
other sources. dcfldd is designed to make verifiable
copies, suitable for use as evidence.
(The name comes from the Department of Defense Computer Forensics Lab,
where the tool was invented.)
Some examples of cpio and pax will be shown below. dd and tar were discussed in a previous course. Google will show many tutorials for all these
commands, if needed; the man pages are only good for reference.
Additional
Points
If you
need to backup large (e.g., DB) files, use a larger blocksize for efficiency.
Many
types of systems can use LVM, ZFS or some equivalent that supports snapshots
for backup without the need to taking the filesystem off-line.
NAS
(and some SANS) systems are commonly backed up with some tool that supports NDMP (the Network Data Management Protocol), which usually works by doing
background backup to tape of a snapshot.
This has a minimal effect on users of the storage system.
If you
need to copy file hierarchies (e.g., your home directory and all
subdirectories), one popular (and good) way is to use tar, like so:
tar
--xattrs -cf - some_directory
| \
ssh remote_host 'cd dir && tar --xattrs -xpf -'
You can do this with pax as easily:
cd dir;
pax -w -x pax . | \
ssh user@host 'cd /path/to/directory && pax -r -pe'
To ensure the validity of backups
and archives, you should compute and compare checksums. Here’s one way when using tar:
tar
-cf - dir |tee xyz.tar |md5sum
>xyz.tar.md5
Many archiving tools ignore extended
attributes (and hence, ACLs and SE Linux labels). Backup and restore by saving ACLs (or all
extended attributes) to a file, then applying the file after a restore, as
follows:
Backup:
cd dir; getfattr -R --skip-base .
> backup.attrs
use normal backup tool here
Restore: cd dir; use
normal backup tool here
setfattr --restore=backup.attrs
rm
backup.attrs
Or
use an archiving tool that supports extended attributes, ext* attributes, and
ACLs: star
H=exustar
-xattr
-c
path >archive.tar
and to restore use: star -xattr -x <archive.tar
(The POSIX standard
tool pax can support this, but
only when using the non-default archive type “pax”. Run “pax
-x help” to see if the pax
archive type is available on your system.
Modern Gnu tar has “--xattrs” option to use with the -c or -x
options; using this forces the pax archive type.)
Additional Tools
Jörg
Schilling’s star program currently supports archiving of ACLs and
extended attributes. IEEE Std
1003.1-2001 (“POSIX.1”) defined the “pax interchange format” that can handle
ACLs and other extended attributes (e.g., SELinux stuff). Gnu tar handles pax and star
formats. There is also a spax
tool that supports the star
extensions.
Another
tool that supposedly easily and correctly backs up ACLs, ext2/3 attributes, and
extended attributes (such as for SELinux) is “bsdtar”, a BSD
modified version of tar that
uses libarchive.so to read/write
a variety of formats.
Amanda
(a powerful network backup utility, producing backup schedules automatically
but relying on other tools for the actual backups. Most other tools don’t support schedule
creation.)
BackupPC (an “enterprise-grade”
utility)
Bacula (works very well and is popular
but has a steeper learning curve than most. See also Bareos,
a fork of Bacula by some of the original developers.)
bru
(commercial sw)
Clonezilla
(similar to commercial Ghost)
HP
Data Protector (commercial sw, used at HCC)
unison (uses rsync)
LuckyBackup (similar to Unison)
vranger
(commercial sw, designed for VMware backups, from quest.com)
foremost, ddrescue, ...
These are not backup tools, but recovery tools when a filesystem is
corrupted and you need to salvage what you can.
Duplicity (Uses rsync to create encrypted tar
backups.)
Rsnapshot (A wrapper around rsync. Rsync is not designed for backup, but can be
used for that in some cases.) This tool
makes a copy of any files modified since the last snapshot (which takes a lot
of disk space), and makes a hard link to any unmodified files.
rdiff-backup (stores meta-data in a
file, so can easily restore files to alternate systems. Usually produces smaller backups than
Rsnapshot, is easier to use, but is slower.)
This tool stores the diff between the newest version and the previous
version. Thus, restoring a very old
version can take a long time. This tool
also can provide useful statistics.
Storix (supports AIX & Linux).
s3ql (backs up to Amazon's S3 cloud).
grsync (GUI for rsync).
Other
tools can be used to backup (or migrate) data across a network, including tar pipped through SSH, BitTorrent
(can use multiple TCP streams at once), and others.
cpio examples:
cd /someplace/.. #
the parent of “someplace”
find someplace -depth \
|
cpio -oV --format=crc >someplace.cpio
# crc=new SysVr4 format with CRCs
Note that when creating an
archive, “-v” means to print
filenames as processed; “-V”
means to print a dot per file processed.
# Restore all; -d means to create directories
if needed;
#
-m means to preserve modification
timestamps:
cpio -idm < file.cpio
# Restore; wildcards will
match leading dot and slashes:
cpio -idum glob-pattern <file.cpio
Without the -d option, cpio won’t create any directories when restoring. Without the -u
option, cpio won’t over-write
existing files. Add -v to show files as they are extracted
(restored).
cpio -tv < file.cpio # table of contents (-i not
needed but allowed)
Command to backup all files:
find . -depth -print | \
cpio -o --format=crc > /dev/tape
Command to restore complete
(full) backup:
cpio -imd < /dev/tape
Command to get table of
contents:
cpio -tv < /dev/tape # -v is long listing
pax Examples (Note you need “-pe” when writing and reading):
# List contents [matching patterns]:
pax -f [-v] files.pax [pattern...]
# Create archives:
find -depth ... | pax -w -pe -x pax
> pax.out
pax -w -pe -x pax -f files.pax path...
# recursive
# Extract from archive:
pax -r [-v] [pattern...] < files.pax
pax -r [-v] -pe < pax.out # -pe means preserve everything
(spax also has -acl option.)
Avoid using absolute
pathnames in archives. tar strips out a leading “/” but cpio and pax do not!
Some versions of pax on Linux do
not fully support “-x pax” (such as on Fedora currently); use “-x
exustar” instead.
To duplicate some files or a whole
directory tree requires more than just copying the files. Today you need to worry about ACLs, extended attributes
(SELinux labels), non-files (e.g., named pipes, or FIFOs), files with holes, symlinks
and hard links, etc. Gnu cp has options for that but cannot be
used to copy files between hosts.
The best way to duplicate a
directory tree on the same host is Gnu cp -a, or if that is not available use
pax:
pax -pe -rw -x pax olddir newdir
To
copy a whole volume to another host you can use dump
and then transfer that, then restore it on the remote system.
Tar or pax
is often used to duplicate a directory tree to the same host if Gnu cp isn’t available. These tools can also be used to duplicate a
directory tree to a different host, via ssh:
tar
czf - -C sourcedir files \
| ssh remote_host 'tar xzf - -C
destdir'
Use tar with ssh if this is a complete tree
transfer. For extra performance, use
different compression (e.g., “-j”
for bzip2). You may need extra options to control what
happens with ACLs, links, etc.
Using rsync
over ssh often performs better
than tar if it is an update
(i.e., some random subset of files need to be transferred). (Show ybsync
alias on wpollock.com.)
(Show backup-etc
script.)
Files or backups and archives can be copied
between hosts with scp or rsync.
Using scp
scp is a simple way to copy files
securely between hosts, using SSH. The
syntax is simple:
scp file... user@host:path
For
example, to copy the file foo to the home directory of ua00 on YborStudent, use
the command “scp foo ua00@yborstudent.hccfl.edu:.” (Note that a relative path is relative to the remote user’s home directory.)
You
can copy in either direction, and scp
has many options to control the attributes of the copied file; see the man page
for details.
Using rsync
rsync is a versatile tool that does
incremental archives, either locally or across a network. It can also be used to copy files across a
network. rsync
has about a zillion options but is worth learning. To understand its options (and diagnose
performance problems) you need to understand how rsync
works.
First,
rsync reads last modified timestamp
and the length of both the source and destination files. If they are the same, it does not transfer
anything. If either is different, rsync reads both the source file and
the destination file, and performs progressively smaller hashes on them, to
determine which parts differ. After this
analysis, rsync copies the
similar parts of the destination file to a new file, and then copies the
different parts from the source file and inserts them into the proper places in
the new file. Finally, rsync copies the updated new file to
the destination file location. Note the
timestamp of the new file is the current time, not the time of the source file;
usually you will need to include the “-t”
option to update the destination file’s timestamp to match the source’s
timestamp.
You
can speed up rsync by
eliminating the new file and updating the destination file in-place. However, that is dangerous if your network
connection is unreliable. It does
preserve hard links though.
rsync uses compression to reduce bandwidth use and
make the transfer faster. You can use
SSH to make the transfer secure.
You can run rsyncd as a daemon on the remote end (port
873). This makes the transfer go faster
(no need to fork rsync each time,
and have it calculate file lists each time), more controllable (via a config
file), and allows you to push files to (say) a Windows disk that has a
different layout and paths. As a server
daemon, rsync acts like a modern, super-charged FTP server
(and is often used to provide mirror sites on the Internet). You don’t get SSH security however.
A
serious performance concern is when copying files from different systems. The timestamps may not match, causing rsync
to unnecessarily copy the whole file.
This can happen when two systems have clocks that are slightly off. It can also happen when using filesystems with different granularity for the timestamps.
For example, most Flash drives use FAT, which records timestamps only to
within two seconds. You need to use the rsync --modify-window=1
option in that case, to have rsync
treat all timestamps within one second as equal.
The syntax is “rsync options source destination”.
Either the source or destination (but not both) can be to remote
hosts. To specify a remote location, use
“[user@]host:path”. A relative path is relative to the user’s home directory on host.
(Filenames with colons can cause problems, not just with rsync.
Colons after slashes work fine, so use “./fi:le” instead of “fi:le”.)
Note! If source
is a directory, a trailing slash affect
how rsync behaves:
rsync -a source
host:destination
will copy the
directory source into the directory destination, so source/foo becomes destination/source/foo. On the other hand:
rsync -a source/
host:destination
copies the contents
of source into the directory destination, so source/foo becomes destination/foo.
One of the reasons
to use rsync over tar is the control it provides over what to copy. You can include or exclude files and directories. For example, to exclude all files or
directories (and their contents) named .git, add “--exclude=.git”. (If
you have files with that name and only want to skip the directories, add a
trailing slash.) To exclude just one
specific directory, you must specify an absolute pathname. Similarly, use “--exclude=*.o” to skip all files ending in “.o”. You
can use glob patterns with some extensions.
This can be complex; see the rsync man page or this summary. Note
that unlike shell globs, there is a different meaning between patterns with
trailing “*”, “**”, and “***”.
If your “--exclude” options (you can specify this multiple
times) skip too much, you can add “--include” options to re-include them.
The archive
(“-a”) option is a shorthand for several
others. It means to preserve
permissions, owner and group, timestamps, and symlinks. The “-z”
option enables compression. The “-R” option copies pathnames, not just the
filenames. The option “-u” says don’t copy files if a newer version
exists at the destination.
If you want destination to be an exact copy of source, you also want to delete any files on destination that weren’t present in source; add the --delete
option for this.
To
make a backup of /home to server.gcaw.org with rsync via ssh:
rsync -avre "ssh -p
2222" /home/ server.gcaw.org:/home
rsync -azv me@server.gcaw.org:documents documents
rsync -azv documents me@server.gcaw.org:documents
rsync -HavRuzc
/var/www/html/ example.com:/var/www/html/
# or copy ~/public_html to/from me@example.com:public_html/
rsync -r ~/foo ~/bar # -r means recursive
rsync -a ~/foo ~/bar # -a means archive mode
rsync -az ~/foo remote:foo # copies foo into foo
rsync -az ~/foo/ remote:foo # copies foo's contents
rsync -azu ~/foo/ remote:foo #don't overwrite newer files
The
meanings of some commonly used options are:
-v
= verbose,
-c = use MD4 (not just size and last-mod time) to see if dest file different
than src,
-a = archive mode = -rlptgoD = preserve almost everything,
-r = recursive, -R = preserve src path at dest, -z = compress when sending,
-b = backup dest file before over-writing/deleting,
-u = don’t over-write newer files,
-l = preserve symlinks, -H = preserve hard links, -p = preserve permissions,
-o = preserve owner, -g = preserve group, -t = preserve timestamps,
-D = preserve device files,
-S = preserve file “holes”,
--modify-window=X = timestamps match
if diff by less than X seconds
(required with FAT, which only has 2
second time precision)
--delete = remove files from destination not present in source,
-z = compress data at sending end, and decompress at destination
Some
other options include using checksums to validate the transfer, renaming
existing files at destination (with a trailing “`”) rather than overwrite them,
and a bandwidth limiting option so your backup doesn’t overwhelm a LAN.
Modern
rsync has many options to
control the attributes at the destination.
You can use --chmod, xfer
ACLs and EAs. You can create rsyncd.conf files, to control behavior
(and use a special SSH key to run a specific command), and define new arguments
via ~/.popt. But older rsync
versions don’t have all those features.
For example, old rsync
had no options to set/change the permissions when coping new files from
Windows; umask applies. (You can use special ssh tricks to work around this, to run a “find ... |xargs chmod...” command
after each use of rsync.)
A good way to duplicate a website
is to set a default ACL on each directory in your website. Then all uploaded files will have the umask over-ridden:
cd ~/public_html # or wherever your web site
is.
find . -type d -exec xargs setfacl -m
d:o:rX {} +
This ACL says to set a default ACL
on all directories, to provide “others” read, plus execute if a directory.
(New directories get default ACL too.)
With this ACL, uploading a file will have 644 or 755 permissions, rather
than 640 or 750.