Object-Oriented Design
Written (C) 2005-2013 by Wayne Pollock, Tampa Florida USA. All rights reserved.
Write your code as if the next person to maintain it is a homicidal maniac who knows where you live. –“Head First Servlets & JSP” p.314
[Some of the following material adapted from Cay Horstmann’s excellent “Object-Oriented Design & Patterns”, (C)2004 John Wiley & Sons, Inc.]
Following a design procedure to produce software (or anything) is an absolute must. (I grant it can be hard for a student to see that from the simplistic programming assignments given in a classroom setting.) There are many reasons for this, some of which are discussed below.
If you are hired as an entry-level software developer (programmer), you will not be expected to be able to design important software systems. But you will need to be able to understand and work with more senior developers (software engineers). They will do “high level” designs (system “architecture” and you will need to fill in the details to make a more complete design. So no matter what you expect to do later, you will need to know about software design.
Legally speaking, “software engineering” (a.k.a. programming) is not a recognized engineering discipline. (This is changing though; the IEEE offers certifications for this.) In other professional fields, not following standard procedures carries severe consequences, including legal penalties. For programmers this means you can’t be sued for mal-practice, but it does account in part for the bad quality of much of the software used. Following proper design, testing, and auditing is often required by government and industry regulations for software quality control.
There are many standards and certifications that apply to software. Most concern the process of development, and rarely force a particular software design choice. These are intended to ensure quality software. Examples include ISO 9000 certification (required to sell software in the EU), DO-178B/DO-254 certification (required for avionic systems), etc. There are also applicable security and safety standards for various industries (such as PCI-DSS standard for handling credit card data, HIPAA for health data, etc.).
ISO 12207 is a standard for software lifecycle processes. It aims to be “the” standard that defines all the tasks required for developing and maintaining (quality) software (although there are other standards used in the world). The standard has the main objective of supplying a common structure so that the buyers, suppliers, developers, maintainers, operators, managers, and technicians, involved with the software development, use a common language.
ISO 9126 is related to the others. It aims to address some human bias from the definition of quality, especially for projects that were started without a proper definition of success in the first place. Unlike ISO 9000, this standard defines the quality of the final project by measuring characteristics (metrics) such as functionality, reliability, usability, maintainability, and others.
So why must you follow a design methodology? Many common programming tasks seem simpler than they really are and can require a genius to get it right. Some of the issues “production” or “professional” quality software should address include thread safety, resource management (e.g., memory or resource leaks), security (protecting confidential data), and safety. Following standard design patterns and design procedures means your software will use the best known solutions.
Not following proper design and testing methodology leads to systems that in the past have bankrupt companies and endangered human life (see Wikipedia “Therac-25”. More recently, the CBS-owned TV news station WCCO in Minneapolis-St. Paul, Minnesota reported in June ‘10 that a woman being moved from one nursing home to another died while being transported on the 22nd of April because of a software problem in the ambulance's onboard oxygen system.)
See (and avoid!) this list of the top 25 errors from SANS.org, made when developing software.
More and more often, software developers are getting sued (or losing judgments in binding arbitration) for not following industry best practices and standards, including ethical standards. (This applies to project management too.)
Another reason to follow proper design methodology is cost. Changes and fixes cost 10 times as much to do in the design phase as in the analysis phase, and 10 times as much to do in the implementation phase as the design phase. (Don’t even think about changing the requirements or design in the maintenance phase!)
When changes requested by the customer will cost a lot, they may not realize that. (From their point of view it might seem a simple change.) In such cases you should explain the costs involved and give them choices; “Can that wait for version 2.0?”, “If we do that, what other feature can be drop for now, so we can finish on time and under budget?”.
Proper design helps eliminate many problems, such as missing proper checks for under- and overflow, data validation, graceful degradation (fail gracefully, not endangering life or corrupting data during a failure), or a non-accessible user interface. All “production quality” software needs to meet several requirements beyond what you find in formal requirements documents. The software should meet requirements for security, reliability, availability, fault tolerance, adaptability, human safety, interoperability, long-term evolvability, and trustworthiness. The software should provide diagnostic ability (logs and assertions), testability, and support audits (both security and compliance) and assurance evaluations. Enterprise applications should have contingency plans in place if dependent on data centers and networks operated by other organizations (i.e., the cloud).
Basic Concepts and Terminology
Before OOP, software was designed by identifying the algorithms to be used. Next, the data types were chosen to make those algorithms easier to implement (and more efficient). The problem with this approach is that it doesn’t scale up to very large programs. Consider that a web browser might have 1,000 procedures, all of which have access to the same data. If designed using OOD, you may end up with (say) a set of 100 classes, each of which has 10 methods. The 100 classes are implemented independently, and their objects only interact in a limited fashion.
This object-orientation makes the larger problem understandable (you only need to understand a few classes at a time while coding). It also limits where to look for bugs; if the data in some object is wrong, you only need to examine the one class to see where the problem could possibly be.
Traditional procedure-oriented design usually starts at the top, a method called main in most programming languages. Then you decompose the problem into smaller sub-problems, each of which can be further decomposed. Eventually, you should reach a sub-problem that is small enough that you know what algorithm to use for it.
With OOP, there is no real top. (While there is generally a main method, it is only used to create a bunch of objects, build the user interface (the “UI”), and initialize databases and network connections.) Instead, there is a bunch of objects talking to each other, in response to events. This takes some getting used to; where do you start program design? The answer is, you must first decide what objects (and thus, what classes) are needed. This is discussed further, below.
From the point of view of an OOP designer, objects are things that have identity, behavior, and state. A class describes a group of similar objects. Each object of that class has the same methods and fields (data, or state) as every other. However, no two objects have the same identity, even if otherwise similar (e.g., in a purchasing system, two Order objects have different identity even if they are orders for the same items). An object’s identity never changes for its lifetime.
The state is information that objects store in their fields (or properties, or attributes or instance variables or ...). This state allows object methods to remember the results of previous method calls, and to cache data that would be expensive to lookup or calculate each time. Thus the required state is what is required to implement the object’s methods.
In (nearly) every design, the state is private and accessible only to the methods. In this way, the exact implementation of state is not part of the public interface to the object and can be changed as needed, without fear of breaking anything.
The behavior of an object is determined by the set of its public (and protected) methods and constructors. This is determined by the design. However some methods determined by the design may be too complex to be easily implemented or tested, or may contain duplicated functionality with other methods. Such methods can be broken into several smaller private methods. Note that only the public methods define the behavior; the rest of the code is implementation detail that can be changed as needed.
Sometimes the best way to implement state and behavior is to define “helper classes” and use such objects to hold state information or to implement some behaviors. Such classes should not be visible outside the current package. In some cases using private nested classes is a more convenient or efficient implementation.
Software Projects are developed in phases: initial idea, requirements specification, design, coding, acceptance testing, delivery, and maintenance. These phases often overlap in time, and some phases get repeated.
You need to set deadlines for each part of a project, called milestones. These are deliverables. In many real-life situations, the deadlines are set starting with the management mandated delivery date. However there is a temptation to skimp on the initial analysis and design this way. Always allow sufficient time for design and analysis. If you don’t you won’t make your deadlines anyway.
Software lifecycle stages — Steps to Develop Software
The activities of software design, development, and support (maintenance) can be grouped into distinct stages or phases. In each phase the activities you do are different. These phases may be done in sequence, over-lap, or iteratively (where you go back to earlier phases again and again). Broadly speaking, you can define the first three phases as:
1. Analysis (initial idea + overall design) Here you need to determine what the software should do. The results of this should be the requirements or specifications. (Also called Software Requirements Specifications, or SRS.) Initially you have a vague description (a project proposal, sometimes called a RFC or RFP), but you must determine complete and exact requirements, including performance and cost. Remember that what is obvious to the VP of marketing that created the project proposal may not be obvious to you or other developers! Two common ways of doing specifying the requirements (usually both are used) are:
· Use cases (or scenarios) A use case is a description of a sequence of actions to accomplish some task. It is like a storyboard, showing each step of the user interaction with the system. A set of use cases can fully describe the requirements of a system. This can also be called task flow or workflow. It is also known as a business process.
· Functional (text) specification A functional specification must fully describe all the terms and concepts needed, then using these describe every task. It is difficult to make a functional specification that is complete, unambiguous, free from contradictions, and readable. However these specifications are usually the best way to document performance requirements (e.g., uptime, min. sustained load, burst loads, response time). (Often, a combination of these techniques is used.)
A part of the requirements, often overlooked, is technology requirements. The customer/client may be assuming a certain type of server or middleware or EIS technology, or just assuming a hardware budget much too small for the application and performance requirements expected. For example you need to make sure you and the customer/client understand and agree on the platform used (cloud, cluster, SAN, etc.), memory and disk space available, network bandwidth available, specific database product to use, etc. It pays to find out what products they already have, and have local expertise with.
2. Design Here you determine the objects required to fulfill the requirements. Quite often the initial design of a complex software system won’t cover every detail, just the overall design. This can also be called the system architecture or sometimes the system model. A software engineer or senior developer may (for example) specify the architecture as a set of “modules” and their responsibilities, and leave the details of designing individual modules to others.
A good design should be as simple as possible, and extensible in light of the fact that requirements change over time. (It often pays to think about the more likely potential changes and have a design that would make implementing such changes cheap and easy, later.)
The design is sometimes called logical modeling. (It is sometimes followed by another design sub-phase, physical modeling, which means roughly the same as the implementation. Sometimes “physical model” is the name given to a database schema to be used with the software system.)
The design process can be broken down into the following three steps, each comprises several sub-tasks and related concepts. Note however they are not done in this order. Rather you jump around the steps, repeating as necessary.
A. Identify the classes. The really means identify the objects required. This often starts with looking for nouns in the requirements documents. In the end, some proposed classes will be trivial and end up as simple primitive types (or Strings) and thus as fields of other classes. Some proposed classes have no behavior and are really just database records. Each proposed class should have a single responsibility or a (very) small set of related and interdependent responsibilities. Only experience will help you pick the right classes.
After finding the easier proposed classes, you need to think about the big picture (the system architecture). What else is needed to make the design complete? You should mentally run through the use cases and make sure your design can fully support each one.
Consider a voice-mail system. What are the obvious objects? (users, messages, mailboxes, passwords, phone extensions) What else? (Menus that can be altered over time, or perhaps multi-language menus, timestamps.) These are the obvious objects, but how will messages be stored in mailboxes? You need a queue (or FIFO), perhaps several (for new and saved messages). Here is a list of categories of classes; which do you need?
· Things (real-world items, devices, systems). Whole systems (VoiceMailSystem) are convenient top-level classes that can contain a main and system initialization and shutdown code.
· Actors, users, agents, and roles. (Often have names ending in “or” or “er”, e.g., User, Administrator, Student)
· Events and transactions (e.g., Sale, Update)
· Collections and other foundational (standard library) classes (Set, String, Rectangle, Date)
Name your classes with names that are descriptive of (an) object of that class: Message, not Messages (unless the object is a collection) or MessageObject or Msg. Avoid generic class names such as User, Agent, Item, Event, etc. If the obvious name turns out to be a verb (e.g., BuildX, MakeX) then you should rethink the design. (This can happen if the name is just a noun; the tip-off is if the class has a single “doit” method!) If the obvious name contains the word “and”, you should rethink the design.
“One of the tests I use for my program design ideas is whether the thing I’m thinking up has an obviously suitable name. Trouble thinking of a name for a class or method is a warning sign that it may not be a really good idea.” Patricia Shanahan, posted in comp.lang.java.programmer on 28 Jul 2011.
Identifying classes is hard! With experience, you learn to avoid having one “master” overly complex class plus a bunch of trivial classes. Each class should do some of the work. (Qu: Why?)
B. Identify the responsibilities (behaviors) of the classes. Responsibilities are at a high level of abstraction. This means, don’t try to determine the methods required at this point. A typical responsibility might be “Manage Passwords” rather than listing “read password” and “update password” methods. You find these by looking for the “verbs” in the requirements.
Responsibilities often fit into a natural ordering or layering (level) of abstraction; that is, some responsibilities are low-level (processing mouse-clicks), middle-level (Manage passwords) or high-level (initialize the whole system). When assigning responsibilities to classes/objects you should make sure all the responsibilities are at the same level for any one class.
Each responsibility becomes one or more public methods of the class; everything else discovered later is implementation details and should be private. When doing this step you will often determine state or instance variables are needed in order to do the tasks you identified.
Classes should have neither too many nor too few responsibilities. A class with none is probably a foundational class and is too trivial to worry about. It becomes an attribute, for example a class Point, or a database record.
All the responsibilities of a class should be related. If not, you probably should split the class into two or more simpler classes. Ideally, every class should have between 1 and 3 responsibilities. The degree to which all the parts of a class related to each other is known as cohesion. One goal of your design is to have classes with a high degree of cohesion.
Don’t add responsibilities that aren’t required, even if it seems that implementing them would be easy!
C. Identify the relationships between the objects. A bunch of independent objects that do not interact would make design, implementation, and testing very simple, but the resulting system would not be very useful. The degree in which different objects depend on each other is known as coupling. A goal of your design should be to minimize coupling, and to use standard design patterns when you must have two or more objects interact.
Loose coupling is also called the Law of Demeter (LoD), or the Principle of Least Knowledge.
In general, we say that interacting objects are collaborating and have an association or dependency or link between them. Three common types of association are:
i. Dependency: (commonly called the uses-a relationship) Class A depends on (or uses) Class B if objects of class A examine or manipulate objects of class B.
For example, consider a purchasing system with Account, Order, and Item classes. Order class objects may invoke an Account object’s methods (say, when ready to check out and place the order). I can imagine a method call such as “Order.addToAccount(customer);” from the Order object’s checkout button event handler.
In this case, Order uses-a (has a dependency on) Account. Of course, it is possible to have Account objects invoke methods of Order objects too. (Think about a display recent orders button.) So there could be a uses-a relationship in either or both directions. But, Item objects have no relationship with Account objects.
The lack of any relationship between class Account and class Item means these classes are completely independent. They can be designed and built independently. Any bugs in one, even a design flaw that requires one to change the public methods, won’t have any effect on the other class. This is very desirable, and is known as loose coupling (discussed further, below).
Typically, the association is transitory, with a method of a class A object invoked with an object of B as an argument.
Consider a voice-mail Message class with the responsibility of playing itself. One design of a method to play the message could be:
public
class Message {
private AudioClip message;
public void play ( Device dev ) {
dev.output( message );
} }
This design has the Message, Device, and AudioClip classes coupled, and we can say that a Message uses-a Device. (And if you look carefully you’ll see that Device uses-a AudioClip too.)
A good design will minimize coupling and thus minimize dependency. What if we give the responsibility of playing the message to a Device object? The revised Message class might then look like this:
public
class Message {
private AudioClip message;
public AudioClip getMessage() {
return message;
} }
Both designs would work, but the second has less coupling and would thus be a better design. (Qu: What would the Device.play method look like?) Note that unless the Message class has some additional responsibilities not shown here, the class becomes a useless wrapper around an AudioClip.
ii. Aggregation: (the has-a relationship) This is the association when one object contains objects of some class over a period of time longer than a single method call. (We’re not talking about parameters to methods or local variables.) A MessageQueue object could be said to has-a Message object(s). Think MANAGES-A or OWNS-A for aggregation.
Not all instance fields of a class correspond to aggregation. A single instance of some foundation class (String, Date) is really just an attribute of one class, not an association between classes. This distinction is very subjective, but if in doubt, prefer an attribute to an aggregation.
In some cases you can distinguish between regular aggregation and composition (“is-a-part-of”). If some object X is created and destroyed when the containing object Y is, and is never referred to by other objects, the relationship between X and Y is composition. (Examples: “titlebar is-a-part-of a window” is composition, but “doctor has-a patient” is aggregation.)
iii. Inheritance: (the is-a relationship) This is actually an association between classes, not individual objects, and has been discussed previously.
With either dependency or aggregation, the association has a property called multiplicity. This can be 1:1 (one student object has one ID number) or 1:n (one to many, as in one MessageQueue has up to n messages). A 1:* multiplicity means an unlimited number (or none at all). A multiplicity of 1:0..1 would mean either zero or one; the zero is often represented by setting the instance variable to null. (Aside: Using wrappers such as Integer instead of primitives such as int allows you to distinguish between not having the attribute (null) and having it with a value of zero.)
Which design is best? Often there are many possible sets of classes that would appear to fulfill the requirements. Rather than go with your first design, spend a little time thinking of the alternatives. In the end it may not matter which design you chose, but often one design is simpler, more efficient, or more extendable then another. (Another school of thought, extreme programming or “XP”, says the opposite: Just do the minimum now, and add only as needed.)
CRC cards: On the top of a 3x5 index card, write the proposed class’ name. Down the left side list the responsibilities, and on the right list the other classes that collaborate with this one. Make new cards, rip up old ones, add and cross-out responsibilities and collaborators freely. (Show CRC resource.)
3. Implementation This phase starts off with building the “stubs” or skeleton of all identified classes and methods. An IDE such as Eclipse has wizards to do this for you.
stubs are empty methods, except that methods that return values must have a return statement (that returns some fake but realistic value). A skeleton class is one with only stub methods and constructors.
A skeleton class can in fact be compiled. As you implement classes and methods one at a time, this skeleton becomes a prototype, a not quite production-ready version of the project. The prototype is expanded and filled in until the whole project is complete. This works well for small and medium sized projects, but more formal implementation processes (with testing and design and code reviews) are needed for larger ones.
It sometimes pays to ‘do one design to throw away”, just to gain insight into the problem and possibly to tweak the design before building the production (non-prototype) version. (You can gain insight also by trying to implement some methods.)
Before starting the implementation, the extreme programming method (and other agile methodologies such as rapid prototyping and Scrum) would have you write a set of test cases that “cover” the design. This means there should be enough test cases to test every method of every class in your design, except perhaps for the trivial getter/setter (accessor/mutator) methods. The test cases should also cover the interactions between classes. This is sometimes called test driven development (TDD).
You should schedule (plan) the implementation steps. It is common to implement methods in an order that facilitates testing, or use by other developers working in parallel with you. You often build some methods and classes now, and defer the others until later. The order may depend on developers’ schedules.
Don’t make the (beginner’s) mistake of implementing the “easy” methods first, and saving the “hard” ones until later! Start with the hard ones; they are hard because the design may not be complete or well structured, and you may have to go back and change the design to fix that!
A design that leads to classes and methods that can’t be implemented (while meeting performance requirements and project deadlines) is a bad design.
When implementing code using an IDE such as eclipse, it can automatically write much of the code for you. Common examples include having the IDE generate all the get and set methods for the properties of a class. Even once the code is written a good IDE can help re-work the code, a process today called refactoring.
To some extent each of the software project phases is independent of the later ones. In general, you shouldn’t worry about the design when doing the analysis, or the implementation when doing the design. In reality, the design will be influenced by the implementation choices available to you, and the requirements will be influenced by design considerations. (If not, you often end up with unrealistic requirements, or requirements that would cost a lot more than they should.)
Delivery and Deployment, and Maintenance
Maintenance is the most expensive part of most software projects. It takes the most time. Over the life of the software system, bugs will be found and enhancements requested and implemented. Each change makes the code deviate a little more from the original design. Over time, the resulting “evolved” code gets harder and harder to maintain. Eventually a point is reached when it doesn’t pay to maintain it or enhance it anymore, and support is discontinued. (We say it has reached its end of life, or has been “EOLed”.)
Entry level positions for programmers often have them deal with this maintenance as their main job. You sign into some trouble-ticketing (or issue tracking or software project management or ...) system and work on whatever tickets have been assigned to you. (In some cases, programmers can see what tickets have been entered into the system and choose which one(s) to “own” and work on.) Popular software for this include the commercial product JIRA (which has Eclipse and NetBeans support), and some open source (and free) products such as Bugzilla and Trac.
[From an article in Communications of the ACM Feb. 2011 by Thomas Limoncelli.] Creating software that can be managed, deployed easily, and updated, should be among the design goals and requirements, but usually isn’t. Keeping in mind applications may need to be deployed on hundreds of PCs and enterprise applications on large clusters, try to ensure your product:
· Has a silent install (non-interactive mode with all custom options settable from the command line or from a file);
· Has a non-GUI admin interface. System admins need to be able to script actions to make them repeatable.
· Uses text based configuration (“config”) files. Don’t require a Windows registry setting and don’t use a binary format. This allows system admins to examine, update, and “diff” configurations using standard tools.
· Provides a management interface that not only says if the (enterprise) application is up or down, but also bandwidth/throughput, memory used, and CPU utilization.
· Have a mailing list or RSS feed to report security issues, bugs, and patch availability. (And report security issues as soon as known to the outside world, even before you have a patch available, so system admins can monitor the application for intrusions.)
· Uses standard logging systems (that interface to the OS standard logs, syslog for Unix/Linux and Event logs for Windows.
· Keeps all its files in one (or a few standard) directories. (Don’t put DLLs in C:\Windows or a dozen other locations!)
· Provides documentation on-line. And not just for the currently supported releases but all versions! (The disaster recovery procedure for some 5 year old unsupported installation might depend on being able to find documentation for that version.)
Design Patterns
A design pattern is a standard way to programmatically solve a common type of problem, and is generally accepted as a best practice. (Past generations of programmers used other terms for design patterns, such as “paradigms” and “code idioms”.)
The purpose of design patterns is to capture software design know-how and make it reusable. Design patterns can improve the structure of software and simplify maintenance. Design patterns also improve communication among software developers and empower less experienced personnel to produce better designs.
There are several catalogs of useful design patters on the Internet (Show ootips.org, ...). By becoming familiar with some of these, one can read project proposals and instantly see a pattern that might fit. The book that started it all, Design Patterns, was written by the gang of four (GoF): Gamma, Helm, Johnson, and Vlissides, published by Addison-Wesley. Many new books are available including Object-Oriented Design & Patterns by Cay Horstmann (Wiley).
Examples:
Consider classes Person, Employee, Customer, or classes Person, Student, Instructor. It seems logical to have Employee and Customer extend Person, but what if an Employee buys something, how can you add them to your Customer list? What if an Instructor took a course at HCC? These issues are better understood as roles. A Person at any given time may be either an Employee or Customer or both.
This is a common situation, but tricky to get right in the design. Qu: How would you do this? (Ans: Look up the adaptive role playing pattern and the role modeling pattern, both variants of the classic decorator pattern.) Not inheritance at all, but dependency: Have Student, Instructor classes with a final Person attribute, and (tediously) add forwarding methods.
If you think your design, implementation, and testing would be easier if you could treat Students and Instructors as People, then use a second design pattern too: have a Personlike interface that Person, Student and Instructor fulfills, and Student and Instructor classes merely forward the method call (i.e., String getName() {return thePerson.getName(); ). This is known as the delegation design pattern (and is related to the proxy pattern. Note that a single design can be thought of as examples of different design patterns; the various patterns overlap somewhat.
Some additional patterns include the composite pattern, such as used with GUI containers and components; the decorator pattern, such as a ScrollPane, which adds to (decorates) a pane; and the strategy pattern, in which there are different ways to do something (such as Window layout).
Knowing a few design patterns allows you to communicate more effectively with fellow developers. But, don’t fall into the trap of forcing your code to slavishly follow a pattern, if it doesn’t quite fit.
If your design has many objects that must do DNS lookups, or get a random number, or in general, you have client objects that use a common service, you only want a single instance of the service object. This insures the server can cache results, reuse DB connections, ensure unique random numbers, etc. The pattern is known as the singleton pattern. You can ensure this by making the constructor private (and provide a readResolve() method, which is a pseudo-constructor used in serialization). You then provide a single instance as a final property of the class:
class
Foo
{ private static final Foo foo = new Foo();
private Foo() {...}
public Foo getInstance() { return foo; }
...
}
The singleton pattern isn’t commonly used. The problem with singletons is that they introduce global state into a program, which allows any code to access it at any time (this is called high or tight coupling). This has proven to be bad, often doubling (or worse) development and testing costs. Java EE doesn’t support it well either (you can’t always know which JVM will be used, and you can only make a singleton per JVM).
The best way to make a singleton as of Java 5 is to use an enum with one element:
enum
Foo
{ INSTANCE;
...
}
One aspect of design is the common confusion in situations such as classes Box and Rectangle. It may seem as if a Box is-a Rectangle with a depth (a specialization). But what if I have a collection of Rectangles, one is a Box, and I try to invoke a getArea() method on each? (Boxes don’t have a clearly defined area the way Rectangles do.) By extending Rectangle with Box we have broken our definition of Rectangles.
In practice, objects are defined by their methods. (Eiffel is an exception in that you can specify pre-, post-, and invariant conditions.) But most computer languages only require the name and parameter list be the same to over-ride a method. Unfortunately that makes it easy to mess up!
· pre-conditions – The requirements which a method requires its caller to fulfill.
· post-conditions – The promises made by a method to its caller.
· class invariants – The object state (values of variables at various points) is always valid.
In Java you can (and should) document pre- and post- conditions in the Java doc comments. Proper design leads to the following important principle:
An extension of a class should never modify the behavior (semantics of existing methods) if you treat the extension as though it were one of its superclasses that is, when using over-ridden methods). This rule is called the Liskov Substitutability Principle or LSP. Also known as subsumption. Mathematically you can state this as “Let p be any property of objects of type T. Then p should be true for objects of type S where S is a subtype of T”.
The proper relationships between classes is often a matter of debate. For instance few people agree on the relationship between Square and Rectangle. One good design (and ignoring other shapes including Rhombuses, Parallelograms, and Quadrilaterals) is to have Square extend Rectangle, with both classes immutable. A square is-a rectangle with an additional property that the width equals the height; in LSP terms, all the properties of Rectangles apply to Squares too. Something like the following:
public class Rectangle {
private final double w;
private final double h;
public Rectangle (double w, double h) { ... }
public Rectangle scale (double scaleFactor) {
return new Rectangle( (w * scaleFactor)
(h * scaleFactor) );
}
public Rectangle setWidth (double w) {
return new Rectangle( w, this.h );
}
public Rectangle setHeight (double h) {
return new Rectangle( this.w, h );
} }
public class Square extends Rectangle {
private final double s;
public Square ( double s ) { ... }
public Rectangle scale (double scaleFactor) {
return new Square( s * scaleFactor
);
}
public Rectangle setWidth ( double w ) {
return new Rectangle( w, this.s ) ;
}
public Rectangle setHeight ( double h ) {
return new Rectangle( this.s, h );
} }
Another design possibility is to consider there is no IS-A relationship here. Instead have two classes. The Rectangle class can have an isSquare method, a squareValue method to convert a square Rectangle into a Square (this is a factory method), and a constructor taking a Square.
Another example of LSP is cars. Humans associate “A Ford is a Car” so they make Ford extend Car. They also then say “ModelT is a Ford”, so ModelT extends Ford. The mistake is confusing Make (Brand) with Type (Class), and further confusing Model with Type. This kind of mistake can lead to a very ugly class hierarchy when you end up with classes like FordModelTWithRedPaintAndLeatherSeatsAndPowerWindows.
A simpler design hierarchy would be to have a Car that “has-a” Make (Ford is a Make), “has-a” Model, “has-a” collection of Options (SeatMaterial is an Option) and “has-a” PaintColor.
As a final design example, consider the binary search algorithm shown in COP-2800 (SearchDemo.java). The problem lies with this calculation:
int mid = (low + high) / 2;
This calculation seems correct but contains a hidden assumption: That “low+high” can’t overflow an int. Now that is a reasonable assumption on today’s systems, where a process is limited to 2 GiB of addressable memory. So really big arrays can’t exist. But that isn’t true on all systems, and not on tomorrow’s systems. It won’t allow you to run binary search on a 6 billion name phonebook. This is an undocumented pre-condition.
One possible fix is to document the pre-condition, and let any callers deal with the problems. Another is to make sure that array.length < Integer.MAX_INT/2.
Another way is to prevent any overflow. One way is to do calculations using longs, not ints. Sometimes, a simpler solution is to re-arrange the calculation so that it can’t overflow. Here are several ways (I like the first one, for clarity):
int mid = low + (high - low) / 2;
int mid = (low & high) + (low ^ high) / 2;
int mid = (low + high) >>> 1;
Not all languages have binary operators that are guaranteed to work on ints as Java does (the third solution does potentially overflow, but it still works). Not all languages have any problem; Python integer overflows just promote to an integer type that can handle arbitrarily large values correctly. In C-like languages, note you need to know how computer hardware does math to even be aware of the issue.
Model-View-Controller (MVC)
MVC is a design pattern for structuring enterprise applications. (It also applies to user interfaces; swing uses this.) The idea is to split the code into three parts:
· The model is the code that deals with the application’s persistent data (that is, the database). Rather than scatter SQL statements throughout our code, you create classes with methods to do the updates. These classes are the only ones that need to deal with the database directly. This separation allows you to fine-tune the SQL, change the database from (say) MySQL to PostgreSQL, and not have any of the other code affected. The model has methods to return data (usually requested by the view) and to change data (usually requested by the controller). (Java sometimes uses the term Document for a class that plays the role of a model.)
The model has no user interface. It should have methods that allow the controller to update (change the data in) the model, and for a view to fetch some or all of the data. The model uses events to notify listeners (the view) that the model changed.
Finally, keep in mind that in the model of a GUI component such as a JTable, or JTextArea, there is often two types of data: state of the component (such as position, is enabled, is pressed, etc., and the application data (the contents of a cell in a JTable, or the text in a JTextArea). Components such as JButtons only have the first kind; the model does not store the caption on a button.
You don’t need to know this to use swing, but it does help to understand MVC. (From A Swing Architecture Overview):
Models must be able to notify any interested parties (such as views) when their data or value changes. Swing models use the JavaBeans Event model for the implementation of this notification. There are two approaches for this notification used in Swing:
Send a lightweight notification that the state has “changed” and require the listener to respond by sending a query back to the model to find out what has changed. The advantage of this approach is that a single event instance can be used for all notifications from a particular model — which is highly desirable when the notifications tend to be high in frequency (such as when a JScrollBar is dragged).
Send a stateful notification that describes more precisely how the model has changed. This alternative requires a new event instance for each notification. It is desirable when a generic notification doesn’t provide the listener with enough information to determine efficiently what has changed by querying the model (such as when a column of cells change their values in a JTable).
Lightweight notifications uses ChangeEvents and a ChangeListener. JButtons uses these, for example. Some stateful notifications include TableModelEvent (used with JTables) and DocumentEvents (used with JTextAreas).
· The view is the user interface. This is typically a combination of HTML, CSS, JavaScript, and some programming code (in Java, PHP, or some other language supported by the web server). The code in the view is typically used to fetch needed data from the model, validate user input (before passing it to the controller), and update the display when necessary (for example, a session time-out, or the model has been updated). By keeping this code separate you can easily support multiple user interfaces and not have to make changes to the rest of the code: a web browser-based UI, an executable program run on the client, or an iPhone app.
· The controller is everything else, the “business logic” of the application. When the user clicks on something, the view tells the controller. (In a typical web application, the controller receives a GET or POST HTTP message.) The controller in turn will decide what to do next. It may send a message to the view to show a different web page (or otherwise update the view), or send a message to the model (with the data supplied by the user in a form). The controller may also send an email to someone, send a message to a business partner (for example, order another meal when someone makes a reservation), generate log messages, or some combination of all of these. (Note that if the model gets updated, either the model or the controller needs to tell the view in case it needs updating too.)
There are many variations on MVC, to suit a particular situation. For example, you might combine the controller and view, or split the model into several objects (so the view is responsible for session data such as a shopping cart). Swing does combine the controller and view, into a single component they call the UI delegate. This is because there is a high degree of coupling between the two.
MVC provides several benefits: the project is usually easier to develop, especially in a team (a UI expert can develop the view and a DB expert the model), and the application will scale up (support many users at once), possibly by using a cluster of web servers for the view. Even small applications can usefully apply MVC. (You can think of a web page as using HTML for the model, CSS for the view, and JavaScript for the controller.)
MCV does add some complexity though; you will have many more source code files than if you did it all in one. You may need to use fancy database features (e.g., stored procedures) for performance.
Basic UML
Today it is common to design with pictures and diagrams and less pseudocode. Traditional flowcharts (see for example this flowchart) don’t work well with OOP so other types of diagrams are used. For example, each class could be a box with the name of the class at the top and a list of the class members inside. The boxes might be connected with lines to show relationships between the classes (or objects). Many types of diagrams are possible to show various things, such as class diagrams, object diagrams, sequence diagrams, state diagrams, etc. (You rarely use all types for a particular project.)
Originally every OO book author invented their own graphical notation. Since they all do the same job it was sensible to merge them all into a single notation. Surprisingly this is exactly what happened. The standard is called the Unified Modeling Language or UML. Many books and on-line resources describe UML, and software (both free and commercial) that allows you to create UML diagrams (e.g., violet, argoUML, and Eclipse and NetBeans add-ons). (Show UML PDF guide.) A simplified class diagram:
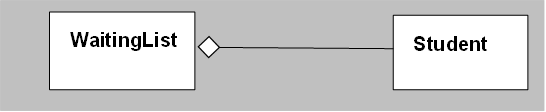 |
The (hollow) diamond line on a solid line shows that a WaitingList object contains (or aggregates) one or more Student objects. A solid diamond show composition, which for Java is about the same thing. Here’s a list of basic UML lines for use in a class diagram:
· Solid line with hollow triangle arrowhead shows inheritance (is-a).
· Dashed line with hollow triangle arrowhead shows interface implementation (show interfaces by using guillemets, i.e., French quotes around the name <<name>>).
· Dashed line with “>” (open arrowhead) shows dependency (uses-a).
· Solid line with hollow diamond shows aggregation (has-a).
· Solid line with no arrows shows association, with a “>” open arrowhead it is a directed association. (This is a more general relationship, not discussed here.)
· Dashed line to a dashed box shows a comment.
Each box represents a class (or interface), with the class name at the top, then a list of (public) fields in the middle (if any), and the (public) methods at the bottom.
The lines many have the multiplicity shown if desired, at each end; if omitted it is assumed “1”. This multiplicity refers to how many objects of one class are involved in the relationship:
* (any number), 0..* (same), 1..* (one or more), 0..1 (either zero or one), n (exactly n).
Finally, the association lines can be labeled (at either or both ends), to show the association details:
[student]----registers for--------------------[course]
Qu: what multiplicity numbers would you put at each end? Ans: “1” at the student end for sure. The other end depends on your design: maybe “1”, maybe “1..*” if your design calls for a method that allows a student to register for several courses at once.
Don’t show foundation classes (i.e., basic classes such as String, Date, Point, Line, etc.) in your UML diagrams.